Advisor Strategy 里最难实现的是弱模型的「自知之明」
4 月 9 号,Anthropic 发了个特别的功能 Advisor Strategy。
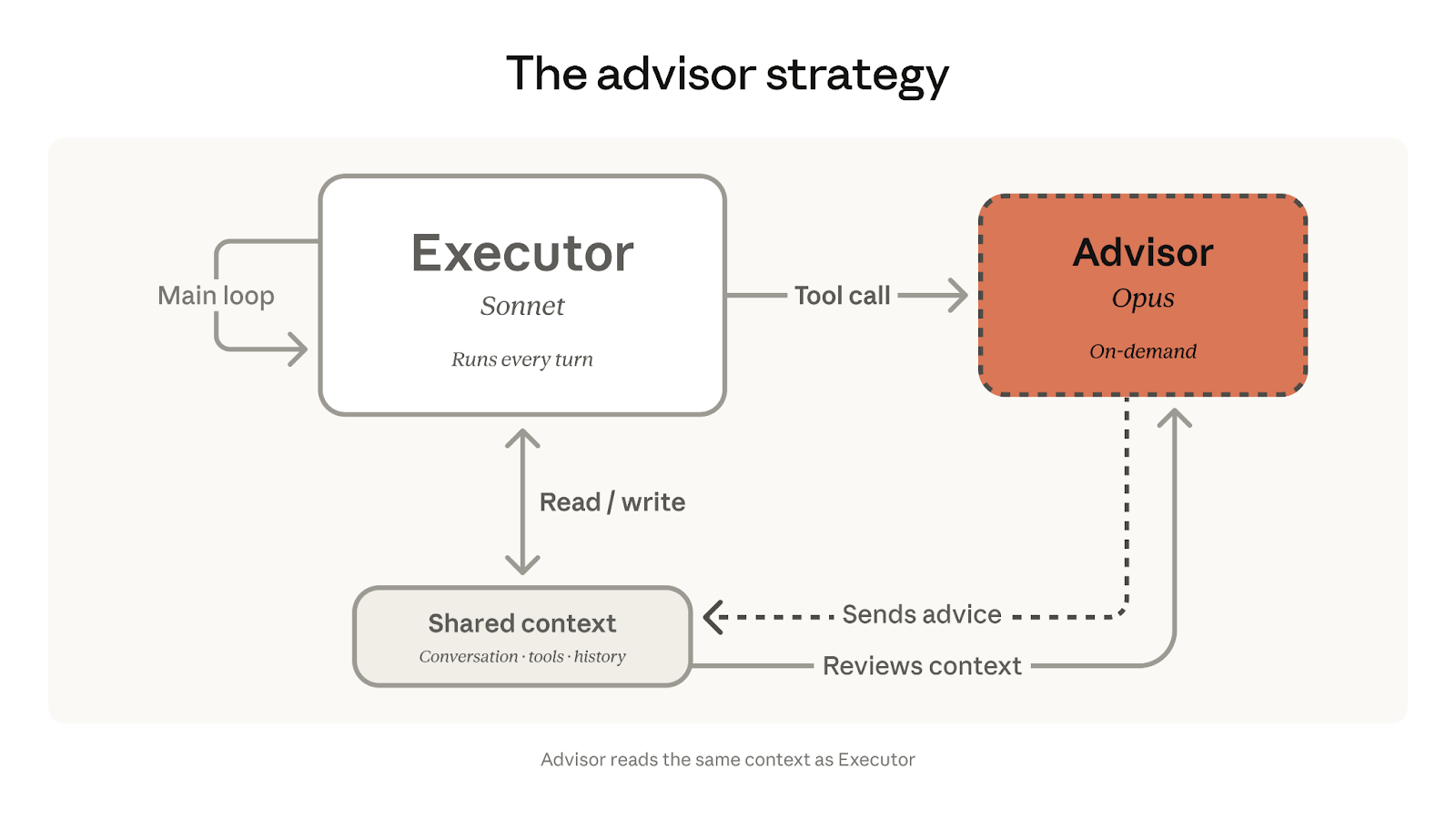
让学生姜维 Sonnet 或 Haiku 先跑任务,遇到搞不定的再请诸葛亮 Opus 出山。
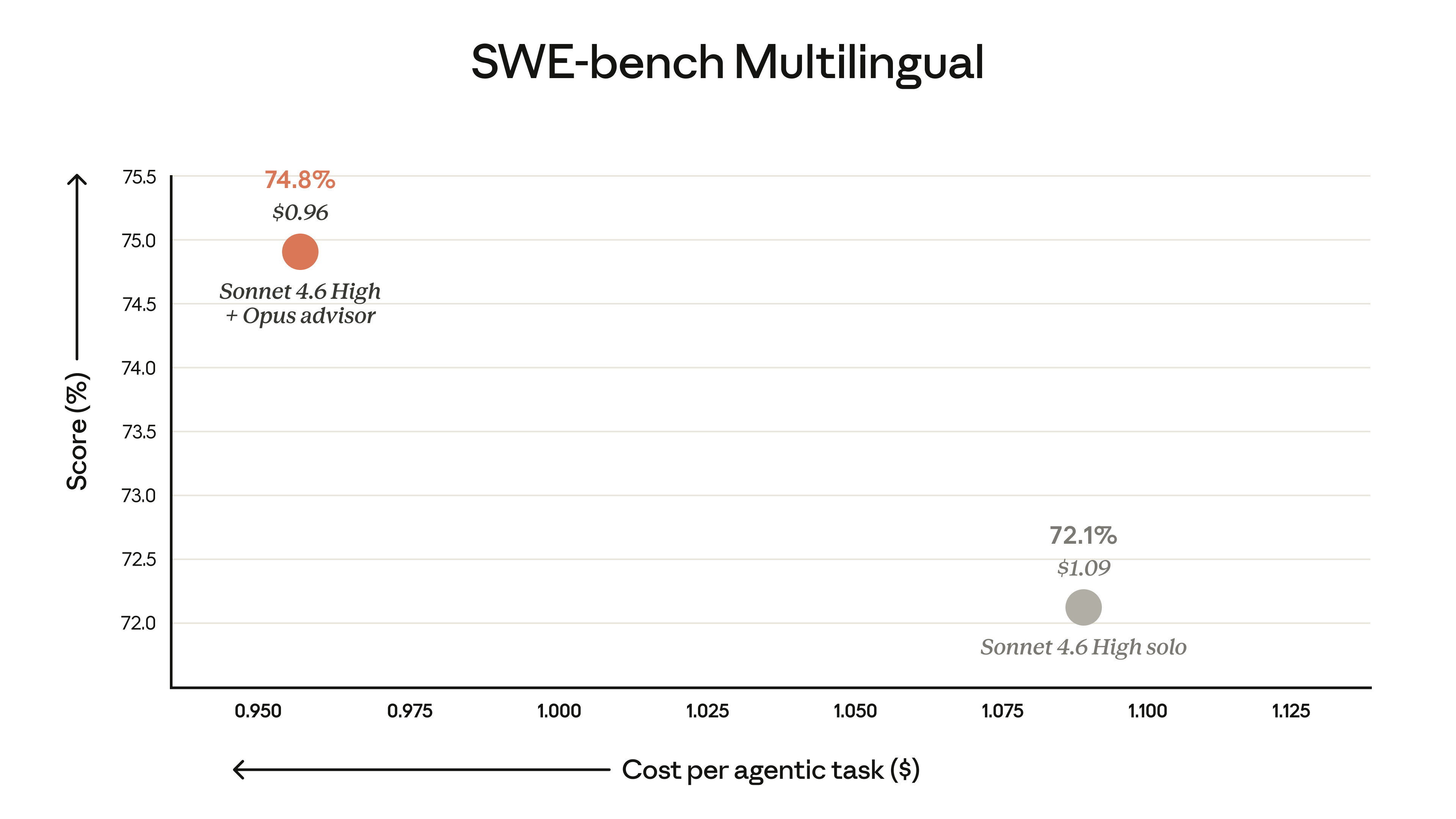
官方跑分数据很亮眼。Sonnet + Opus advisor 在 SWE-bench Multilingual 上比 Sonnet 单独跑高了 2.7pp,成本反而降了 11.9%。Haiku + Opus 更夸张,BrowseComp 从 19.7% 飙到 41.2%,成本比 Sonnet 单独跑还低 85%。
激活的方式很简单:
1 | response = client.messages.create( |
你往 Claude 模型 API 的 tools 数组里加一个 advisor_20260301,完事。整个过程在单次 API 调用内完成,不需要额外的编排层,不需要你自己管理上下文传递。
听起来很美对吧?
但仔细想想,似乎有个被忽略的关键问题:Sonnet 怎么知道什么时候该请教 Opus?
毕竟,熊将之所以熊,就是熊在盲目做决策上,如果有「自知之明」肯请教军师,那还能熊哪去?
反套路的编排模式
Multi-Agent 编排大家天然都是用强的lead弱模型:强模型(Opus)当指挥官,做plan、拆任务,分给小模型(Sonnet/Haiku)去执行。
但这个 Advisor Strategy 把逻辑翻转了:轮到弱模型当carry全程输出,强模型只当辅助。
Sonnet 自己决定调工具、写代码、迭代循环,95% 的工作量都在 Sonnet 完成。只有当 Sonnet 遇到它自己判断搞不定的决策时,才在服务端内部触发一次 Opus 推理,拿到 400-700 tokens 的建议,然后继续。
但这里有个隐含假设:
Sonnet 能准确判断”这个任务我搞不定”。
但这个判断题本身就是个很难的题目,好比你判断自己不知道什么,这比”知道自己知道”难多了。这就是所谓的 meta-cognition(元认知)——一个模型对自身能力边界的感知。
“know to invoke”背后藏了多大的工程量
Anthropic 官方博客的原文是这么说的:
“a server-side tool which Sonnet and Haiku know to invoke when they need guidance or help with a specific task.”
注意,是 “know”,不是 “be told to”。这表明不是你在 system prompt 里写一句”遇到困难就调用 advisor tool”就完了。
Anthropic 提供了一个推荐的 system prompt 模板,大意是:
“在做实质性工作之前调用 advisor tool——写代码前、下结论前、基于假设构建之前。任务完成前也调用一次。超过几步的任务,至少在最终交付前调用一次。”
但这只是引导工具调用频率的,不是教模型识别”这个局面我搞不定”的。
基本的局势判断力得弱模型自己有。
我猜大概率是 RLHF/post-training 阶段专门特训过:给模型大量”应该求助”和”不需要求助”的场景,通过强化学习让它学会识别自己不确定的时刻。advisor_20260301 这个特定的 tool type 也能侧面印证。
类比一下,你可以告诉一个新人:”遇到拿不准的事就问你的Leader”,但他得先有能力分辨什么是”拿不准”。
有些人太怂,屁大点事都要问;有些人盲目自信,捅了篓子还沾沾自喜。
这个判断力不是光靠教科书里一句话能教会的。
两个方向的风险
太怂(过度升级问题):Sonnet 遇到稍微复杂一点的事就问 Opus,advisor 工具调用次数蹭蹭涨,cost 并没有真正降下来。max_uses 参数就是兜这个底的——硬性限制每次请求最多问 N 次。但这也意味着,如果模型过于保守,你可能在最需要帮助的时候撞到上限。
盲目自信:Sonnet 觉得自己能搞定,实际上搞砸了。该问不问,一路错下去。这是很显而易见的失败模式。Anthropic 给的提示词案例模板本质上想约束弱模型在关键节点强制咨询。
但这里有个关键问题:Anthropic 没有公布任何关于advisor准确率的数据。
他们报了最终 benchmark 分数(SWE-bench 从 72.1% 到 74.8%),报了成本(降了 11.9%),但没报:
- 有多少次是”该问没问”(false negative)
- 有多少次是”不该问问了”(false positive)
- advisor 调用的分布是什么样的(是集中在任务开头和结尾,还是分散在中间)
- 不同任务难度下advisor行为的差异
这些数据的缺失,意味着我们无法判断 Sonnet 的 metacognition 到底有多可靠。
为什么这事重要?
1. 不可直接移植
你不能拿 GPT-5、GLM-5 或 Qwen 3.5 之类的当 executor,然后期望它知道什么时候该问 Claude Opus。这个「自知之明」的判断力是 Anthropic 专门训练出来的能力,锁死在 Sonnet 4.6 和 Haiku 4.5 的权重里。

有篇Paper 《How to Train Your Advisor》 研究的是用开源小模型给黑盒大模型提建议。
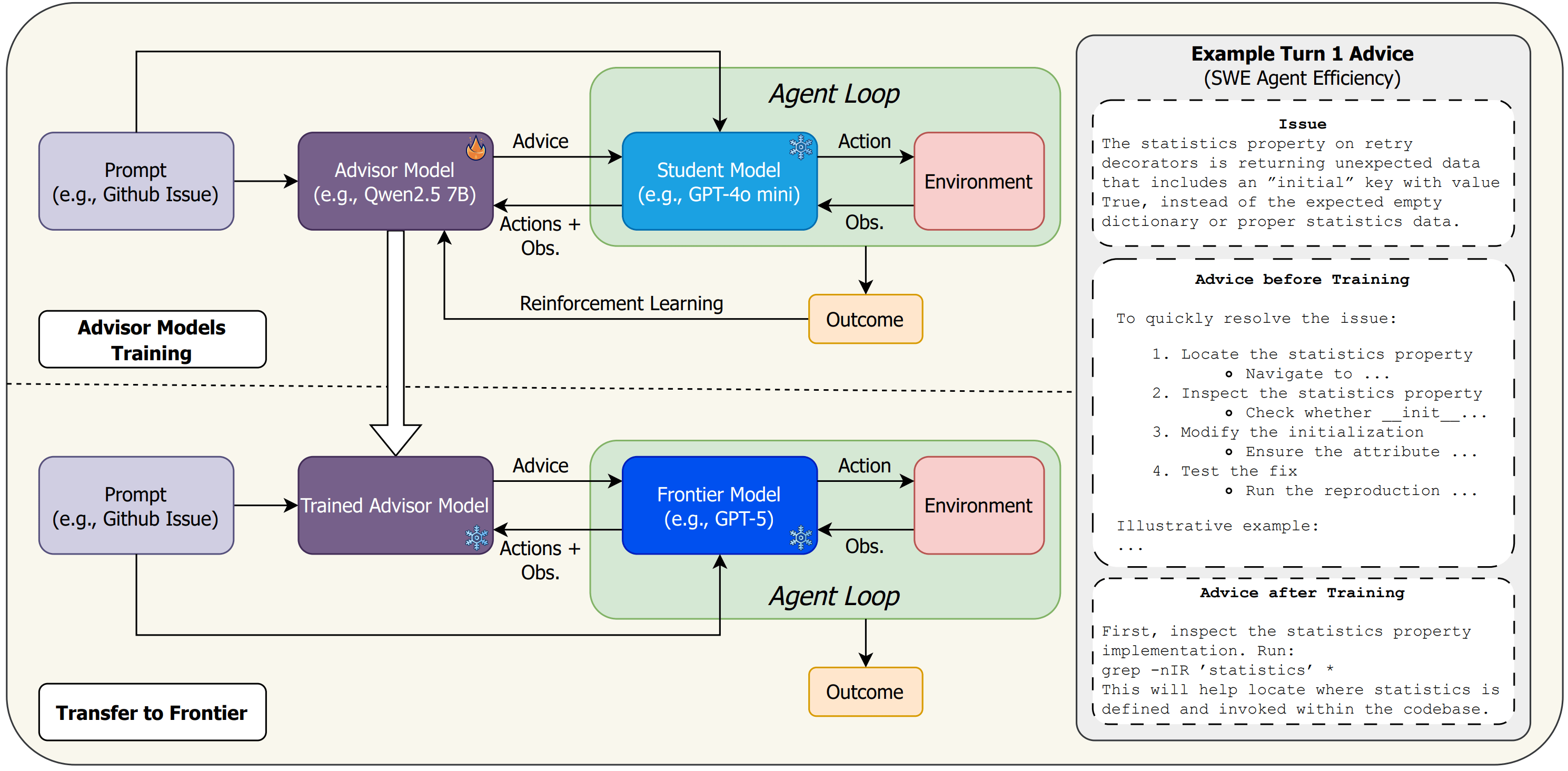
但反过来——弱模型判断何时向强模型求助——这个方向的研究其实少得多。
2. 模型更新要重新训练
Sonnet 4.6 → 4.7 → 5.0,每次模型迭代,知道何时往上抛问题的判断力可能需要重新对齐。
模型的能力边界变了,它对自己不确定性的评估也要跟着变。这不是一锤子买卖,是持续的维护成本。
3. 复现能力
假如你想用开源模型(e.g. Qwen3.5)做 executor + Opus 做 advisor,核心难点不在 API 调用(社区立马有人复刻了一个 。
难点在于怎么SFT Qwen3.5 知道什么时候该求助?要带哪些关键上下文信息?
Anthropic 官方博客的措辞是 “we route the curated context to the advisor model”。注意是 “curated”,并不是完整上下文,而是服务端筛选过的。也就是说,API 内部还有一层上下文筛选机制,决定给 Opus 看多少内容。再叠加上有限的输出 token,advisor 的建议只能是方向性指导,不太可能是手把手方案。这两层瓶颈(输入筛选 + 输出压缩)复现起来远比 API 调用本身难得多。
个人观点
Advisor Strategy 是 2026 年目前为止一个真能让人眼前一亮的 cost-effective agent 编排模式。
它把一个复杂的架构问题(怎么编排强弱模型、多agent协作)降维成了一个后训练问题(怎么让弱模型有自知之明)。
API 谁都能抄,”弱模型知道什么时候自己不行” 这个 meta-cognition 能力才是 Anthropic 真正拿出来卖的东西。
References
- The advisor strategy: Give agents an intelligence boost — Anthropic 官方博客, 2026-04-09
- How to Train Your Advisor: Steering Black-Box LLMs with Advisor Models
- Claude Advisor API: Use Opus for 80% Less Money — Builder.io, 2026-04-12
- Anthropic’s Advisor Strategy: Cut Claude API Costs by Up to 85% — MindWiredAI, 2026-04-13
- An open-source implementation of Advisor Strategy for langchain DeepAgents. https://github.com/emanueleielo/advisor-middleware
Written by Yrom,acquired with 🦐 assistance
Author: Yrom
Link: https://yrom.net/blog/2026/04/21/advisor-pattern-metacognition/
License: 知识共享署名-非商业性使用 4.0 国际许可协议