没有银弹:Agentic Coding 时代的软件工程效率边界
Fred Brooks 在 1986 年关于《没有银弹》的预言,在 2026 年 AI Coding 火热的当下依然成立吗?
1. Fred Brooks 的框架:本质 vs 偶然

1986 年,《人月神话》的作者 Fred Brooks 发表了一篇经典论文 《No Silver Bullet - Essence and Accidents of Software Engineering》 ,他借用亚里士多德哲学概念把当时的软件工程的面临的困难分成了两类:
| 类型 | 定义 | 能否消除 |
|---|---|---|
| Essence(本质) | 软件固有的内在的、不可简化的属性,完全靠人抽象的逻辑思维活动进行概念构建、系统设计 | ❌ 无法消除 |
| Accidents(偶然) | 抽象概念的表达(编码)过程中,工具、实践、环境带来的伴生问题,比如受制于硬件、编程语言特性、研发团队的协作等 | ✅ 可以改进 |
1.1 四大本质困难
Brooks 进一步将本质困难分为了四大类:
- Complexity(复杂性):软件系统的构造之复杂且增长非线性,导致系统的理解、设计、实现、维护等活动变得困难。
- Conformity(一致性):软件的复杂性很多时候是人为强加的,它必须适应各种已经存在的不同的人不同时间为不同原因建立的接口、系统、合规性约束等,没有“放之四海皆准”的解决方案。
- Changeability(易变性):软件纯粹是“思想的产物”,逻辑上极易被修改,永远处于“拥抱变化”的巨大压力状态,用户不断有新需求,而软件也不断适应新硬件环境,而修改成本随系统规模增长
- Invisibility(不可见性):软件无法在物理空间直接可视化她的逻辑实体,摸不到它的”几何形状”,虽然可以画流程图、架构图来描述系统的控制流、数据流等,但这些都是”静态”的描述,无法直观软件的“动态”行为,阻碍了设计者之间的沟通。
1.2 Brooks 悲观的预言:本质困难无法消除
“There is no single development, in either technology or management technique, which by itself promises even one order-of-magnitude improvement within a decade in productivity, in reliability, in simplicity.”
没有任何单一的技术或管理方法,能在十年内带来哪怕一个数量级(10x)的效率提升。
如今,40 年过去了,软件工程的世界天翻地覆, AI Coding 火热的当下,这个论断还成立吗?
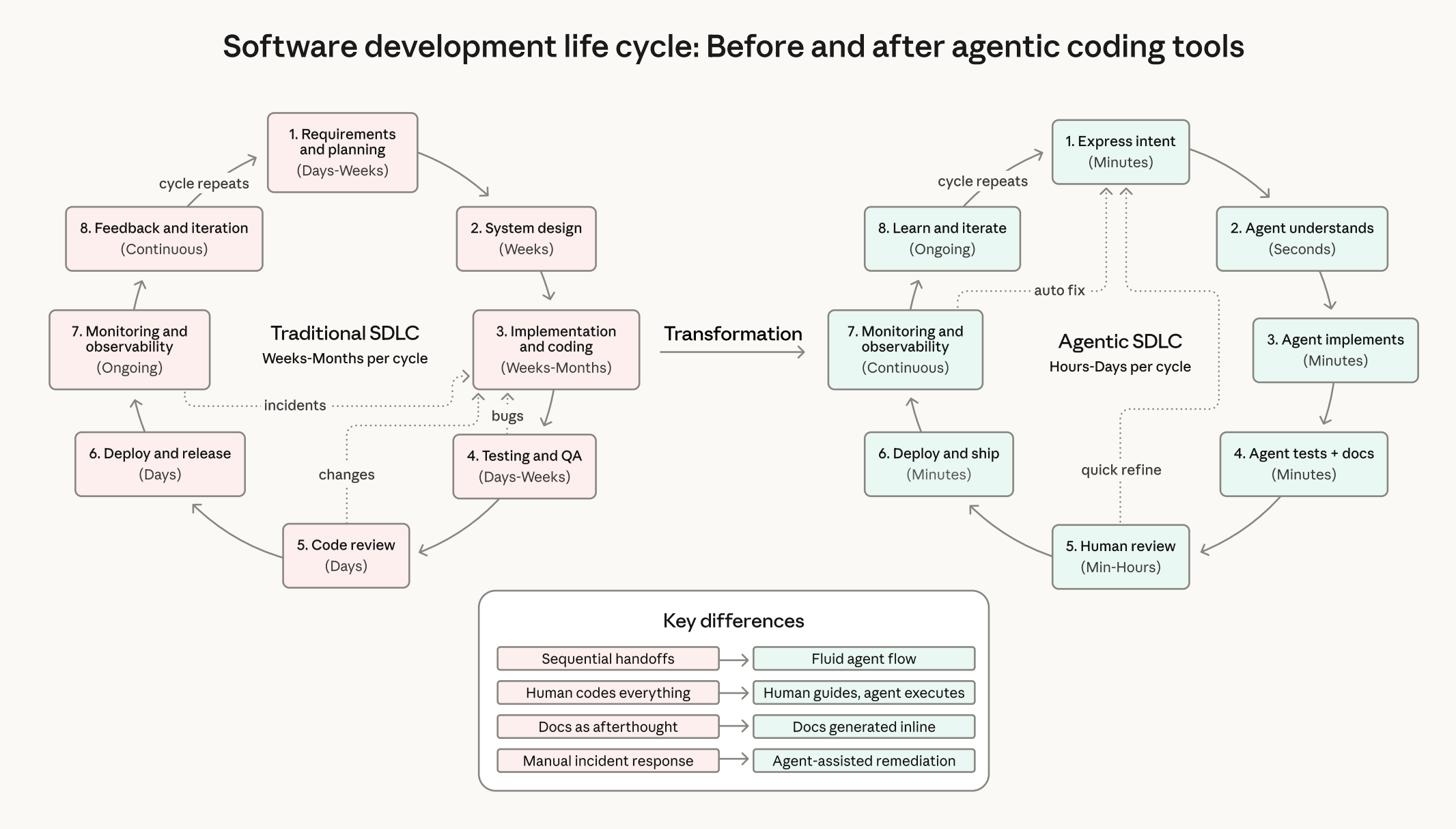
软件开发生命周期从传统到AI迁移图。图来自 《2026 Agentic Coding 趋势报告》by Anthropic
2. Agentic Coding 是当下的效率魔法吗?
2.1 基准测试成绩
⚠️ 数据说明:以下数据基于本文撰写时 2026 年 3 月的公开报告。

2026年2月17日,Claude Sonnet 4.6 发布并炫耀了基准测试成绩
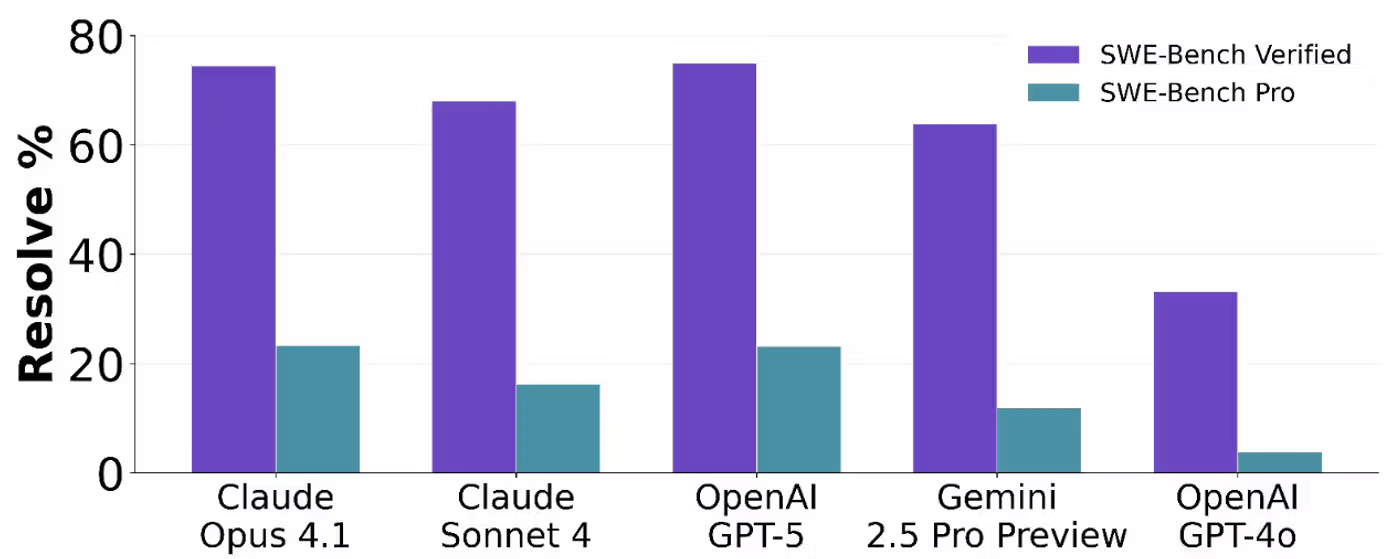
SWE-Bench Pro 与 SWE-Bench Verified 对比
数据来源:SWE-Bench Pro (Public Dataset)
SWE-bench Verified 数据集上前沿模型的问题解决率远超 75%,近期的 Claude Opus 4.6 已经声称解决了80%。
但 Scale Labs 认为该数据集存在”数据污染”问题,早已混入模型的训练数据中,评测数据已经失真。
提出了更接近真实场景的 SWE-bench Pro 数据集。
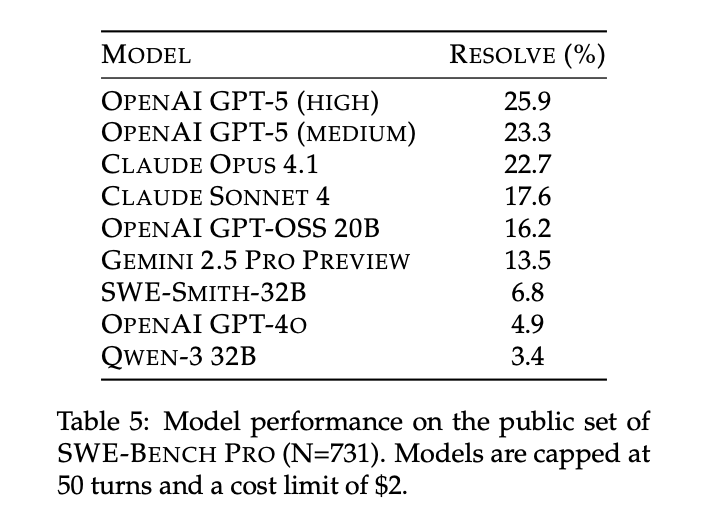
SWE-Bench Pro 论文中当时前沿模型性能对比
而现在,即便最新 OpenAI GPT-5.4-xhigh 仍有 43% 左右的问题无法解决
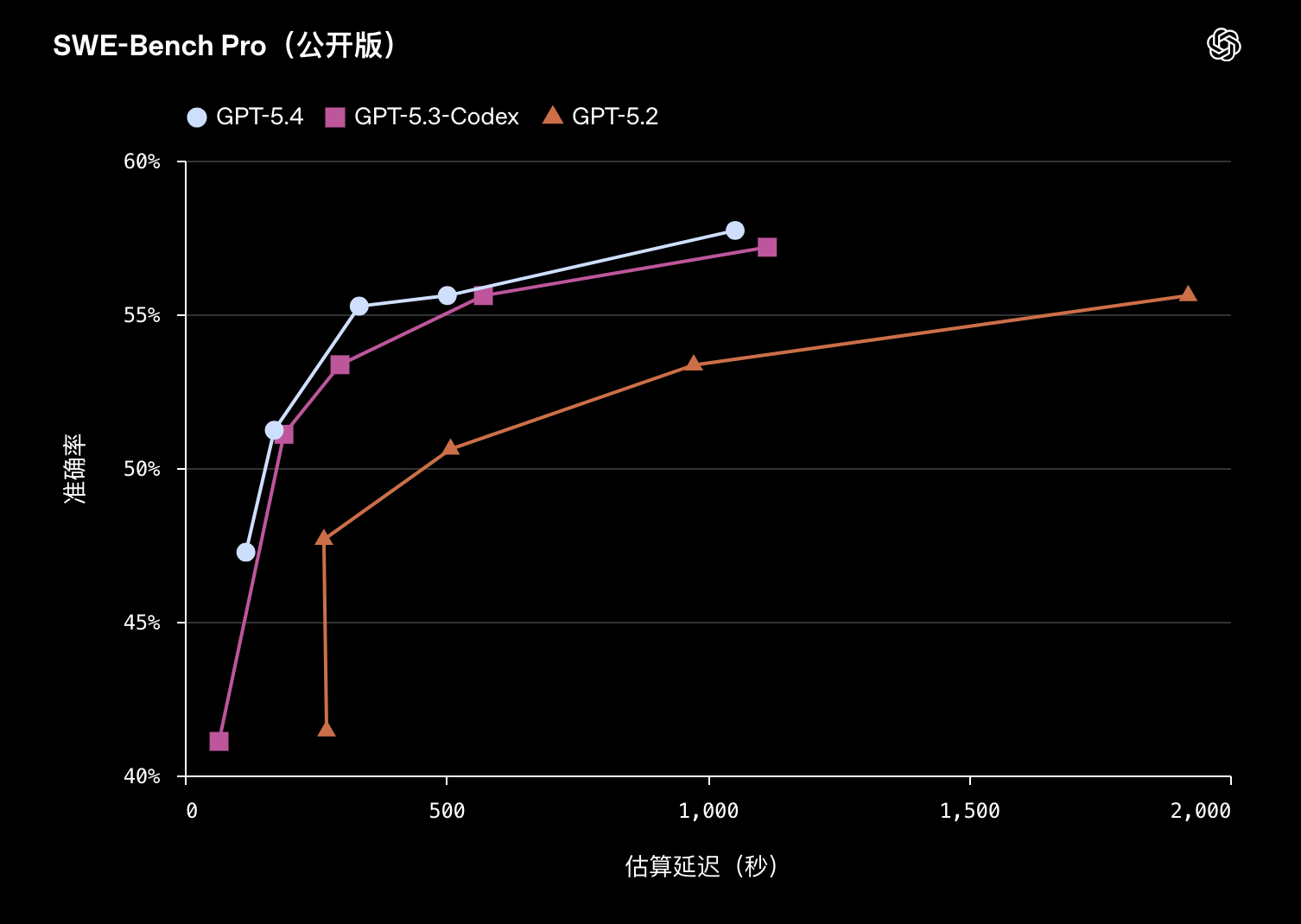
在 SWE-Bench Pro 测试中,GPT‑5.4 的表现超越了 GPT‑5.3‑Codex 或与其持平
来自小红书的研究者在2月份发布了SWE-Bench Mobile 用于评测各种Coding Agent 在小红书内部 iOS 开发场景下的问题解决率。
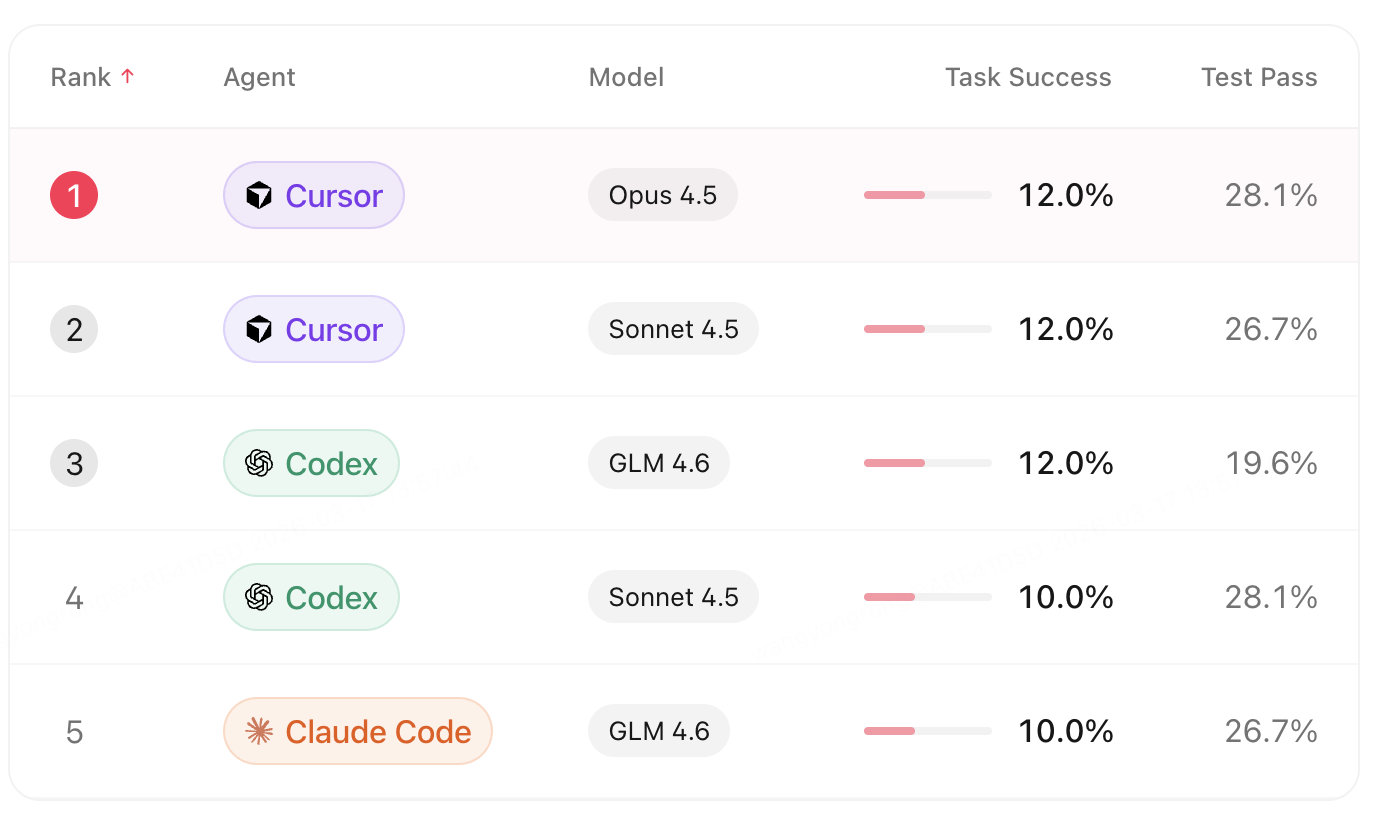
SWE-Bench Mobile 任务成功率。最好的成绩是 12%
Cursor 在3月11日也发布了基于内部真实使用数据构建的CursorBench 基准测试,用于评估各前沿模型在 Cursor 实际应用场景中的表现。
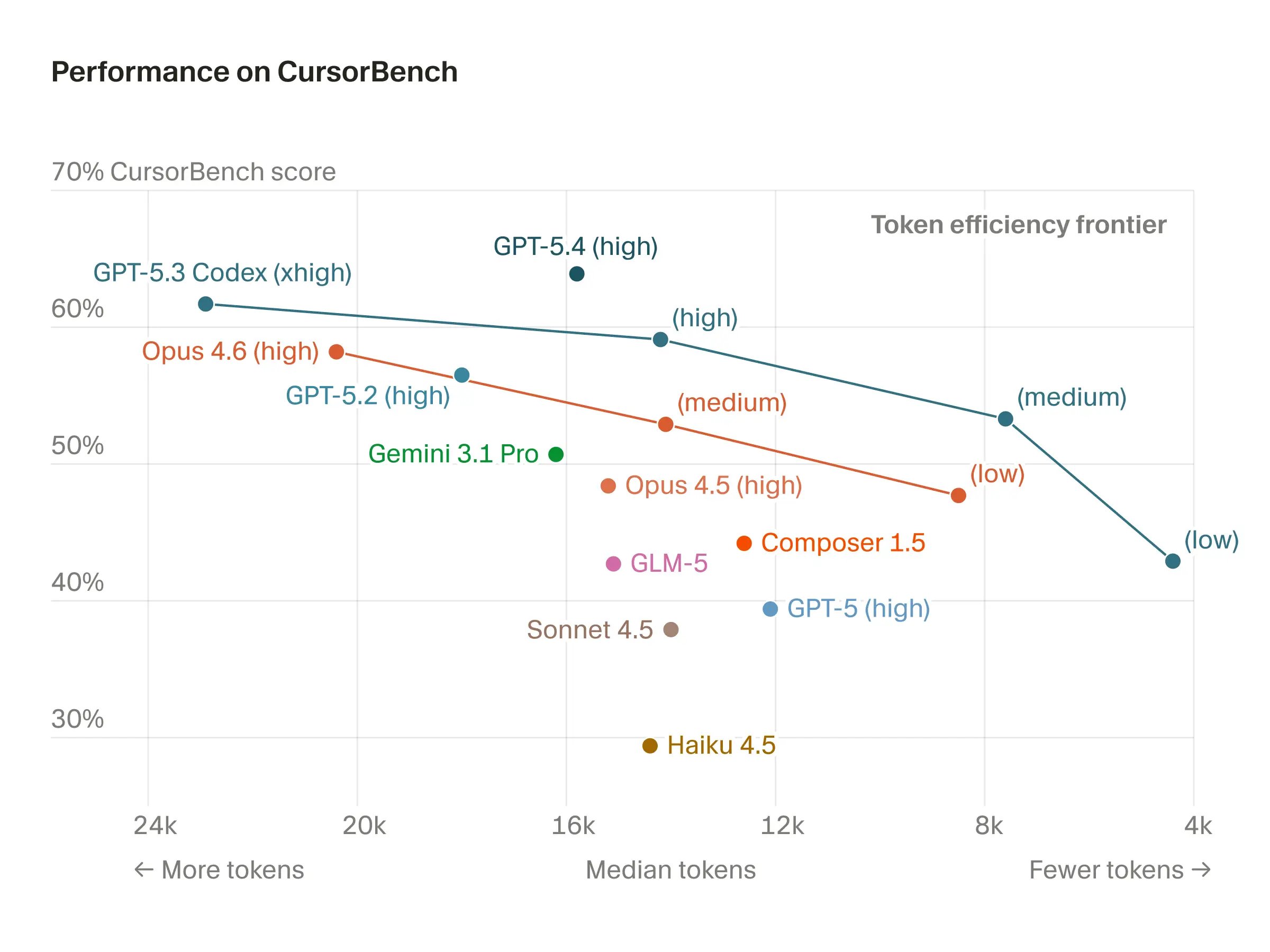
右上角代表理想的智能体质量:以最低成本实现最高性能。
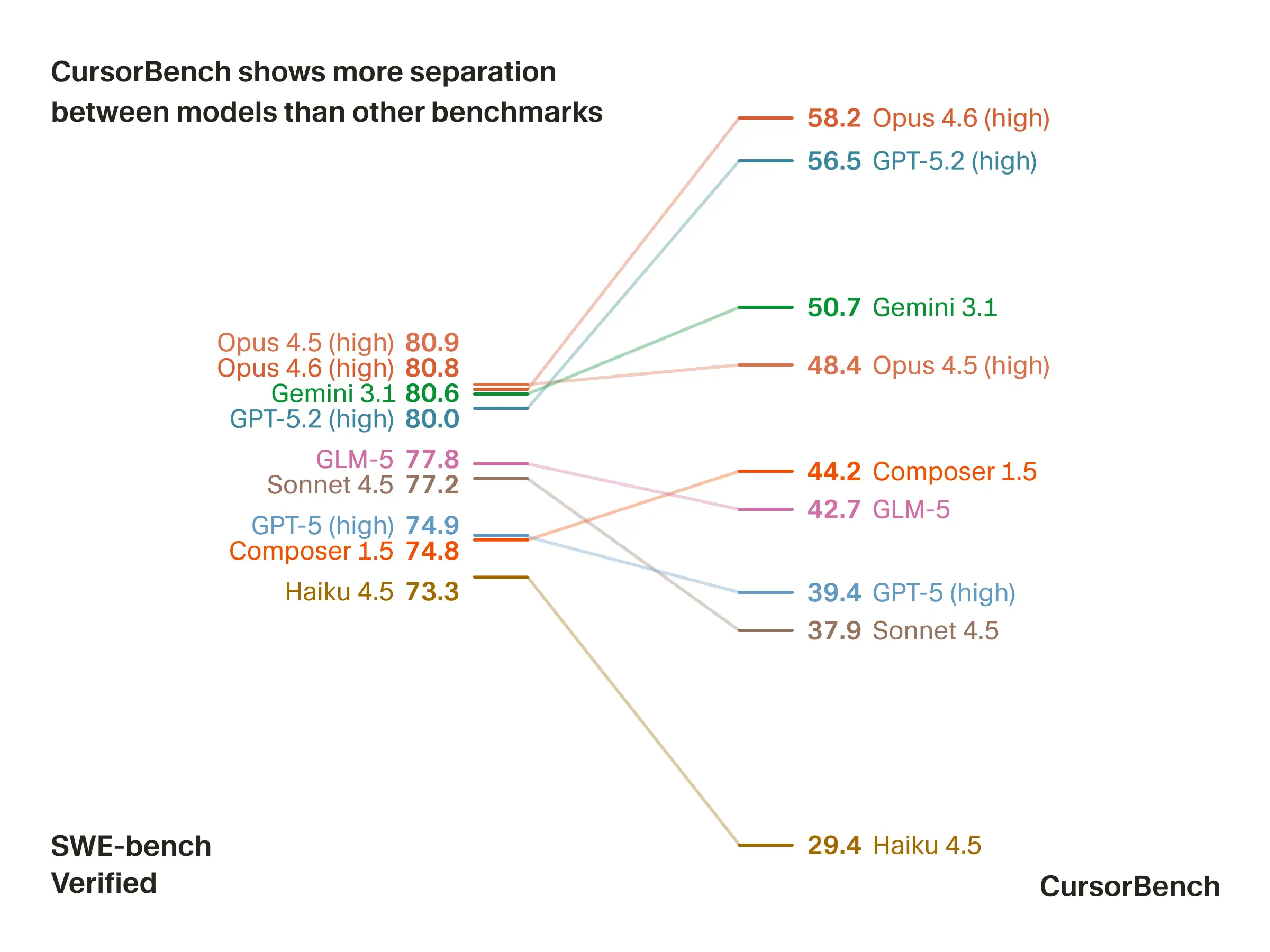
SWE-bench Verified 与 CursorBench 对比
编程最强的 Claude Opus 4.6 标榜自己在SWE-bench Verified 上的问题解决率为 80%,然而 CursorBench 上为 58.2%。
罗列数据只是想表明,前沿模型在实际编程场景里的问题解决率,远低于模型厂商宣传的那样。
2.2 企业级生产力研究报告
| 相关研究 | 关键发现 |
|---|---|
| University of Chicago / Cursor | 采用 Cursor Agent 后,PR 合并量增加 39% |
| GitHub + Accenture | 企业环境中生产力提升 26% |
| Towards AI 分析 | 实际数据支持的提升为 20-30%,而非 10x |
| Faros AI 和 Google DORA 报告 | 高 AI 采用率的团队,PR 合并量增加 98%,PR 平均大小增加了 154% |
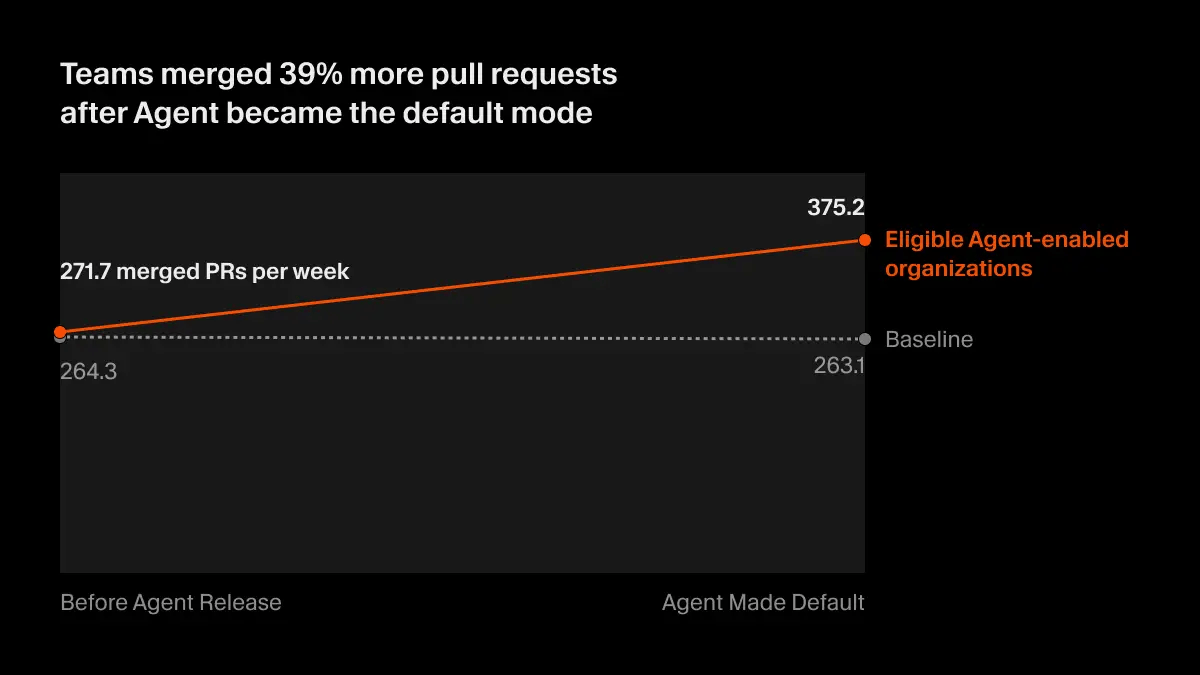
采用 Cursor Agent 模式后,PR 合并量增加 39%。图来自 Cursor 博客
Faros AI 和 Google DORA 报告的数据显示:
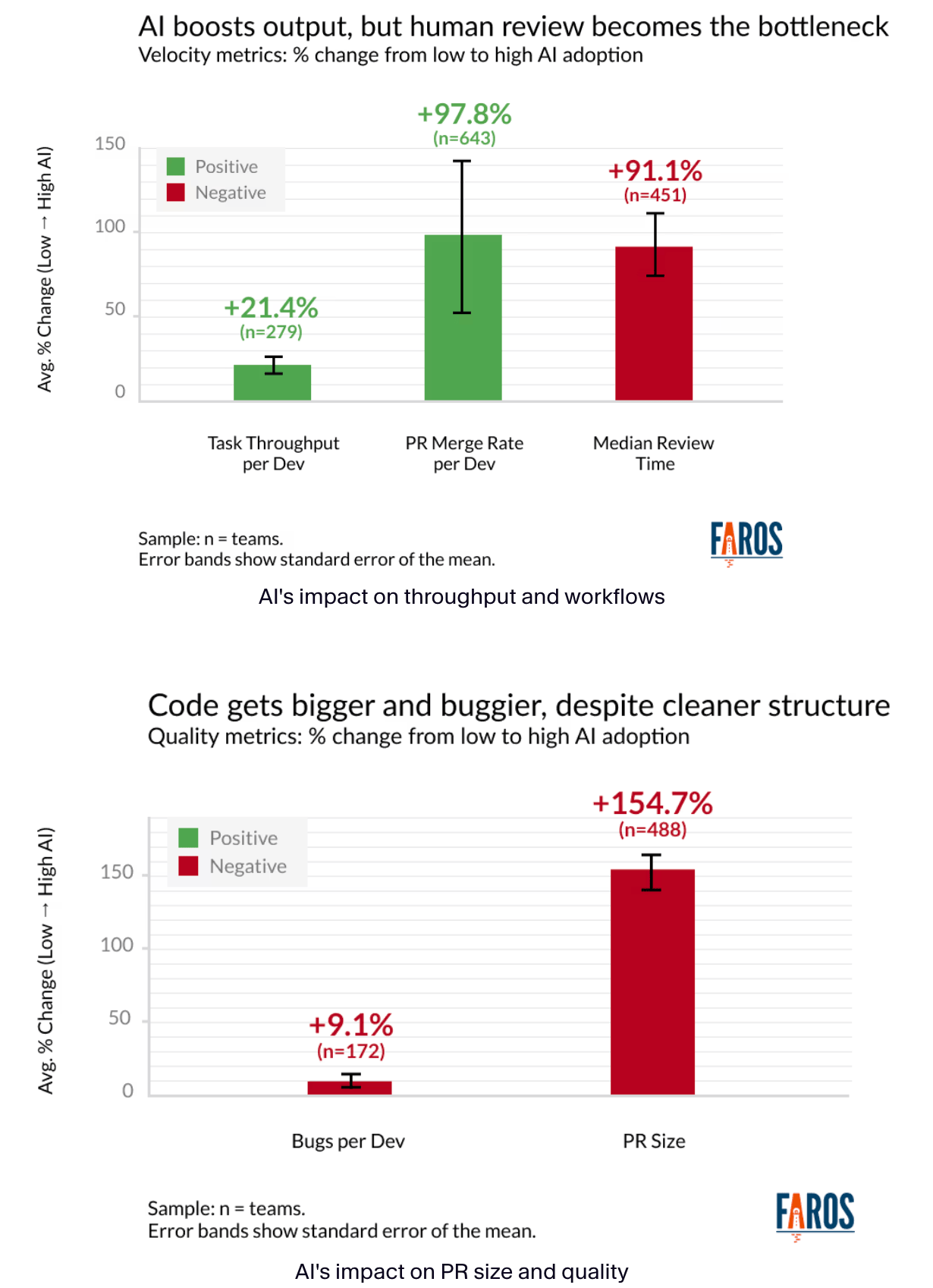
2.3 真的能降低牛马的工作量吗?
是不是所有的研究都支持写代码效率提升,从而促进组织生产力提升呢?
Atlassian 的 2025年开发者体验现状调查报告 DevEx 却揭示了一个信息,虽然 99% 使用 AI 的开发者声称每周节省了 10+ 小时,但大多数人也指出他们整体工作量却没有减少。省下的写代码时间,被组织摩擦(Organizational dysfunction)抵消掉了。
Salazar认为,人们在适应新工具时承受着更高的转型成本:”他们被隐性地要求找时间探索和实验,但日常工作的预期并没有相应调整,以腾出这个空间。”
哈佛商业评论的一篇报告《AI Doesn’t Reduce Work—It Intensifies It》中提到使用 AI 工具并没有减少工作,反而增加了工作:
“In our in-progress research, we discovered that AI tools didn’t reduce work, they consistently intensified it.” …
“Importantly, the company did not mandate AI use (though it did offer enterprise subscriptions to commercially available AI tools). On their own initiative workers did more because AI made “doing more” feel possible, accessible, and in many cases intrinsically rewarding.”
在我们进行中的研究中,我们发现人工智能工具不仅没有减少工作量,反而持续加剧工作量。…… 重要的是,公司并未强制使用人工智能(尽管曾为企业级提供商业化AI工具的订阅)。员工主动做得更多,因为人工智能让“做更多”变得可能、可及,且在许多情况下具有内在的回报感。
越来越多人出来说,AI 让他变得更疲惫。
Steve Yegge 在 《The AI Vampire(AI吸血鬼)》 一文中提到,他在长时间的Vibe Coding 后随时会突然进入瞌睡状态。
“Companies are capitalistic extraction machines and literally don’t know how to ease up. So you’re damned if you do (you’ll be drained) and you’re damned if you don’t (you’ll be left behind.)”
公司其实是资本主义提取机器,永不会松懈。所以你做了你就会被抽干,不做你会被抛弃。
2.4 多少人还在坚持古法编程?
Armin Ronacher 发起的投票 揭示了一个有趣的现象(5000个开发者投票):
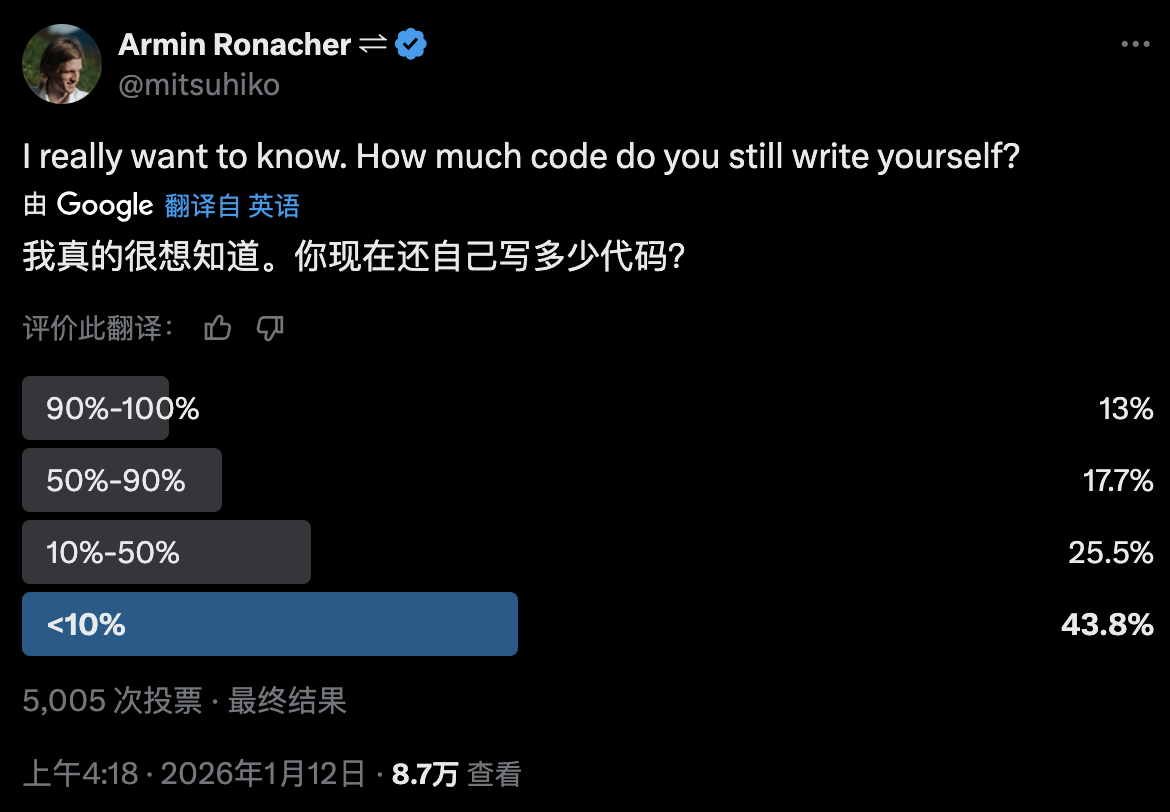
- 44% 的开发者认为,不足 10% 的代码还得手写
- 26% 的开发者手写 10-50% 区间内的代码
这不是正态分布,是双峰分布。一端是像 Andrej Karpathy、Peter Steinberger、Boris Cherney 这样的 AI Coding 狂,每天用 100% AI 写代码;另一端是绝大多数人,还在渐进式采用 Copilot 类工具。
3. 本质困难依然存在
3.1 Complexity(复杂性)
AI 的作用:生成代码、Explore代码库、Discover代码模式
局限性:
- AI 转移了复杂性,而非消除
- 开发者从”理解每一行代码”变为”验证 AI 输出是否正确”
- Ox Security 报告指出:AI 生成的代码”功能完善但系统性地缺乏架构判断力”
AI 错误类型的演变:
Addy Osmani 在他的文章 The 80% Problem in Agentic Coding 中总结了几种典型模式
| 错误类型 | 描述 |
|---|---|
| 假设传播 | 模型早期误解了什么,然后基于错误前提构建整个功能。等你发现时已经五个 PR 过去了,架构早已经固化 |
| 抽象膨胀 | 给它自由,它能过度复杂化。100 行能解决的,它给你搭 1000 行的类层次结构。你得主动推回去:”能不能就…” 回答永远是”当然可以!”然后立刻简化 |
| 死代码累积 | 它们经常不清理自己的烂摊子。旧实现残留。注释被连带删除。不完全理解的代码也被改了,只因它挨着任务 |
| 迎合性同意 | 不怎么 push back。没有”你确定吗?”或”你考虑过…” 只有对你描述的热情执行,即使你的描述不完整或自相矛盾 |
Addy Osmani 认为:真正的危险并不是 AI Agent 会犯错,而是它如此自信地朝着错误的方向前进,你意识不到要停下来检查方向。他呼吁 ”embrace the tools, but own the outcome“ —— 可以拥抱更好的工具,但要为结果负责。
3.2 Conformity(一致性)
AI 的作用:快速学习接口、协议、了解现有模式
局限性:
- 外部约束(API、系统、业务规则)依然存在
- AI 可以更快”读懂规矩”,但规矩本身不会消失
- 集成复杂系统仍需要深度理解
3.3 Changeability(易变性)
AI 的作用:快速修改、重构代码
局限性:
- GitClear 研究发现:代码重构比例从 2021 年的 25% 降至 2024 年的不到 10%
- 更多代码 + 更少人类理解 = 更难维护
- 有预测认为 2026 年将是 AI 驱动技术债务的爆发年
3.4 Invisibility(不可见性)
AI 的作用:解释代码、生成文档、可视化
局限性:
- 软件本质上仍是不可见的逻辑结构
- AI 的解释依赖于 prompt 质量
- “黑盒验证黑盒”的问题:用 AI 验证 AI 生成的代码
- 你甚至已经不看 AI 生成的代码了
4. 新的本质困难
Agentic Coding 引入了新的本质困难:
- 意图精确描述:从”写代码”变成”写 prompt”,精确描述意图本身就是本质困难
- 理解债务:当你的阅读能力跟不上 Agent 的输出能力,code generation bloat 代码生成膨胀,质量问题。
- 生产力悖论:AI 让人”感觉”更高效,但组织的实际产出可能没有显著提升。
4.1 意图精确描述的悖论
1 | -旧的本质困难:如何把想法变成代码 |
Yoko Li 描述 AI Coding 为”上瘾循环”:
“Agent 实现了一个很棒的功能,但可能有 10% 的地方不对。你会想’我只要再 prompt 5 分钟就能修好’。然后 5 个小时过去了。”
总是就差临门那一脚,最后 10% 给你感觉触手可及。再一个 prompt。再一轮迭代。
4.2 理解债务(Comprehension Debt)
当你的“阅读能力”跟不上 Agent 的“输出能力”时,你就不再是工程师了,你是在向 AI 祈祷。prompt 就是你的祷告。
这并不是技术进步,而是一种迁移。你不再手工 Debug 代码,改为微调 Prompt 和妄想去理解 AI 快速生成的大量屎山代码。
Jeremy Twei 在X上提出了一个高度概括的词:Comprehension Debt 理解债务。
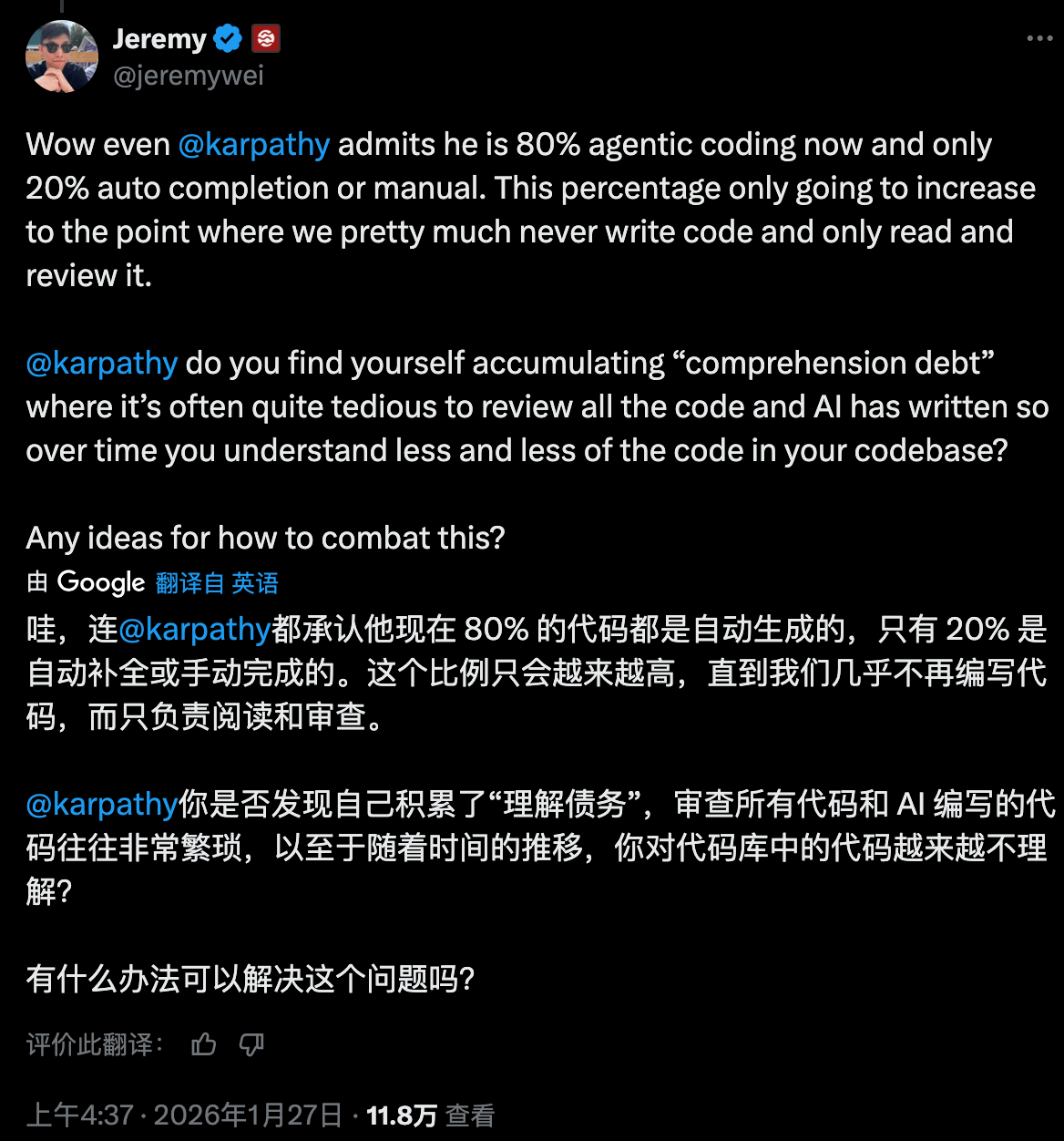
Ana Bildea 在她的文章《The Hidden Technical Debt Inside Your Generative AI Stack》指出:
“Model versioning chaos makes code generation bloat harder to detect. […] I’ve watched companies go from ‘AI is accelerating our development’ to ‘we can’t ship features because we don’t understand our own systems’ in less than 18 months.”
4.3 生产力悖论
Cerbos Blog 指出:
AI 助手让人”感觉”更高效,但实际产出可能没有显著提升
原因:
- 快速生成代码 ≠ 正确的代码
- 完成任务 ≠ 完成正确的任务
- 速度提升被调试时间抵消
换句话说:AI 只能帮你省掉”写样板代码、查文档、调语法错误”这些杂活。但”想清楚要做什么、怎么设计架构、怎么沟通需求”,AI 一时半会儿还替代不了。
5. 总结
Fred Brooks 在 1986 年的预言,在 2026 年依然成立。
Agentic Coding 也许是软件工程史上最强大的工具之一,但它依然不是银弹。
*”The hardest single part of building a software system is deciding precisely what to build.”* — Fred Brooks
这句话在今天依然正确。AI 可以帮你写代码,但无法帮你决定”要构建什么”。AI Coding 甚至可以让你不看一行代码,但并不代表这些本质困难问题就没有了。
它解决了大部分”偶然困难”,让开发者能专注于”本质困难”,如复杂性、一致性、可变性、不可见性,这些依然是软件工程难以解决的问题。
不存在银弹,但能更快Shooting的枪有了。
当码农们习惯了让 AI 写代码,编码记忆会退化、肌肉会萎缩。这就像 GPS 让我们丧失了一定的认路能力、计算器让人口算能力下降一样。那还是当前意义的“码农”吗?
Andrej Karpathy 也极具洞察力的指出AI时代码农的分化:
“LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.”
如果你纯粹是喜欢写代码coding本身,喜欢craft,AI Coding浪潮下,你会感觉无所适从、失去了写代码的乐趣。
如果你喜欢构建东西building,代码只是必要手段,那感觉就像如虎添翼,任自己的想象力翱翔。
来自 Anthropic 的 《2026 年 Agentic Coding 趋势报告》,码农的角色也在发生变化:
Role transformation: From implementer to orchestrator
In 2026, the value of an engineer’s contributions shifts to system architecture design, agent coordination, quality evaluation, and strategic problem decomposition.
但愿新世界能容下这么多Orchestrator, “Agent 指挥官”。
References
- No Silver Bullet: Essence and Accidents of Software Engineering - Fred Brooks
- SWE-bench Official Leaderboard
- Scale Labs SWE-bench Pro Leaderboard
- Cursor Productivity Study
- GitHub Copilot Enterprise Study
- AI-Generated Code Technical Debt Report - Ox Security
- GitClear AI Code Quality Research 2025
- The Productivity Paradox of AI Coding Assistants
- AI Coding Agent Will Not Boost Your Productivity 10x - Here is WHY
- Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity - arXiv:2507.09089
- Morph SWE-bench Pro Analysis
- State of AI 2025 Report
- 2026 Agentic Coding Trends Report - How coding agents are reshaping software development - Anthropic
- The 80% Problem in Agentic Coding - Addy Osmani 2026
- Key Takeaways from the DORA Report 2025
- The Hidden Technical Debt Inside Your Generative AI Stack - Ana Bildea
- AI Doesn’t Reduce Work—It Intensifies It - Aruna Ranganathan and Xingqi Maggie Ye - Harvard Business Review
- The AI Vampire - Steve Yegge
- SWE-Bench Mobile
- CursorBench
声明:本文由 AI 辅助撰写,可能存在错误或不准确的地方。