我做了个 Skill,把论文翻译变成了一行指令
Contents
之前我用过 PDFMathTranslate 翻译 PDF 论文,效果还行。但他有个问题:只能翻译 PDF 文件、只能按页翻译,而且很慢~。其实有时候我只需要翻译部分章节。
无意间,我看到 arXiv 其实提供了PDF的 LaTeX 源码。
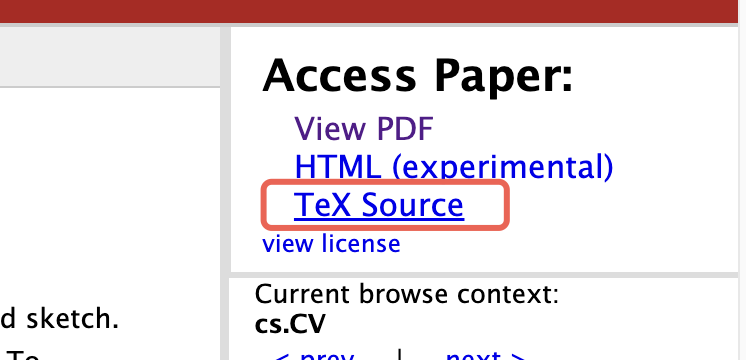
下载一个来解压看,是作者的原始LaTeX。我就想,能不能用Claude Code(或者Opencode)这种AI助手直接翻译 LaTeX 源码?然后编译出中文 PDF 文件!
燃烧吧,GLM 4.7.
是的,我入了GLM 的Coding Plan 的坑,实际体验下来,GLM 4.7 写代码只能说凑合。花钱雇了一个实习生,虽然智力水平够不上博士,平常放着不用就浑身难受,我试了让他翻译翻译论文还是可以的~(虽然,需要花点时间调教
这就是我搞这个项目最初的想法: arxiv-paper-translator
如果你打开看了,这个项目一行代码都没有,它是一个 Agent Skills,封装了从下载 LaTeX 源码、翻译、编译到生成技术报告的完整流程的Prompt。
什么是 Agent Skills
传统的Chatbot,你跟AI对话是一问一答,自己管理Prompt,然后复制、粘贴。
Anthropic 提出了一个 Agent Skills 的想法,并把它变成了跨 Agent 的通用协议。
Agent Skills 把多步骤工作流封装成可复用的技能。
AI 助手(如Claude Code)按预定义流程自动执行,不需要你逐步指导。技能就像一个特化的SOP,整合了领域知识和常见问题的处理方法。
你只需要说「翻译 arXiv 的论文为中文,ID 为:2503.16424」,不用每次都解释「先下载arXiv:2503.16424的Tex源码,然后解压文件,接着翻译每个章节…」
本质上,还是提示词工程。但把提示词拆成模块化的文档(工作流、翻译规则、检查清单),更易维护和复用。
arxiv-paper-translator 做了什么
如前面提到,这是一个把 arXiv 英文论文内容翻译成中文的 Skill。
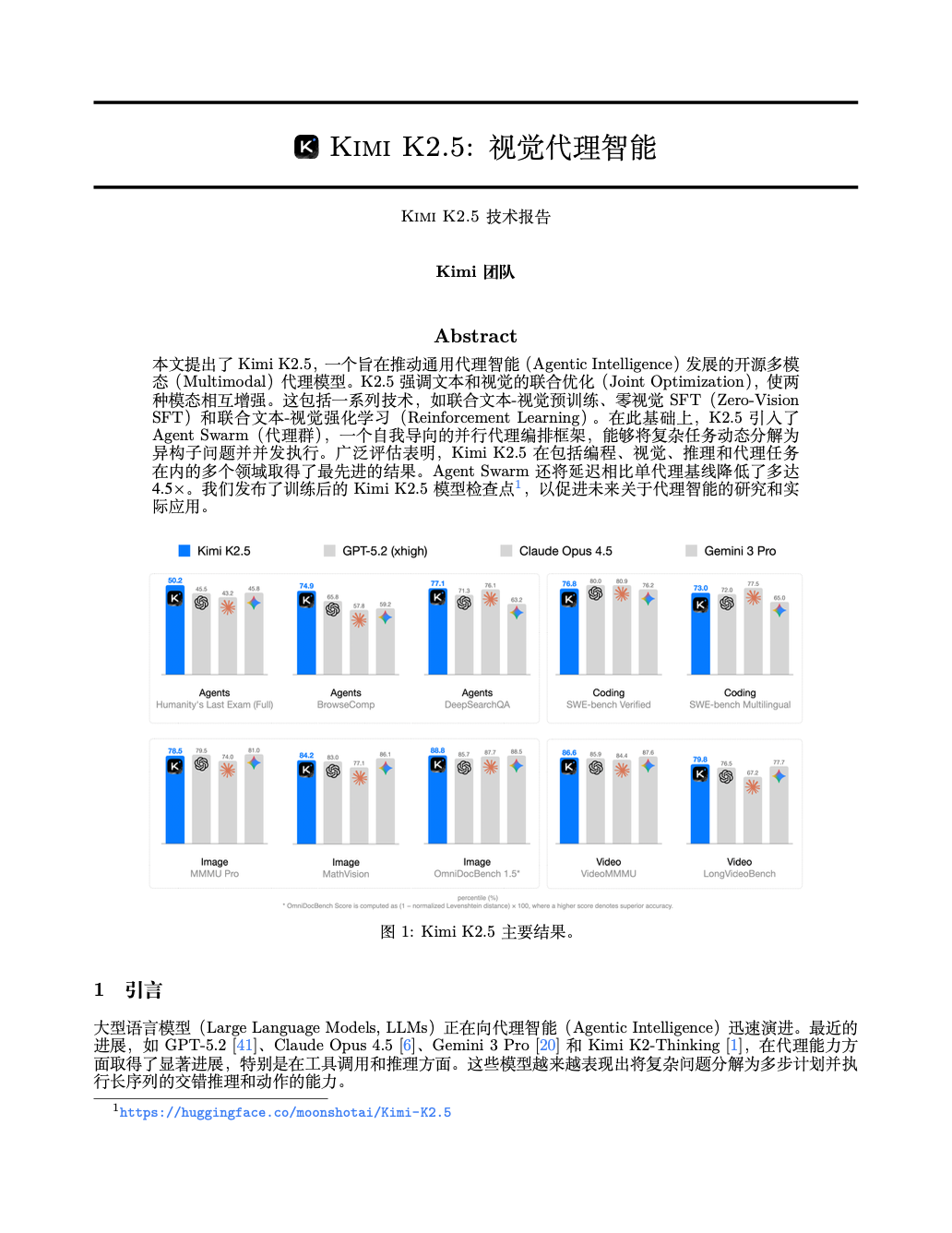
Skill里最核心是基于 LaTeX 源码翻译,这是可以保留论文的原始格式的一种比较好的办法。
 |  |
 |  |
基于 LaTeX 源码翻译
PDF 翻译工具一般都是基于OCR和YOLO (You Only Look Once),会不同程度破坏格式。直接在 LaTeX 源码层面翻译,编译后的 PDF 布局和原论文基本一致(当然不排除一些作者会做一些自定义的排版,导致翻译后字数减少/增多,破坏排版)。
原理很简单:解析 LaTeX 结构,只翻译给人读的文本,保留给机器执行的代码和公式。
1 | % 翻译前 |
章节级控制
调用时可以指定翻译哪些部分:
User: 翻译 arxiv:2602.02276 为中文。跳过附录(Appendix)部分。
AI:Thinking: 用户要求翻译 arXiv 论文 2602.02276 为中文,并跳过附录部分。
根据 skill 的指导,我需要:
- 首先检查本地 XeLaTeX 或 Docker 是否可用
- 下载并提取 arXiv 源码
- 翻译 LaTeX 文件
- 添加中文支持
- 编译生成 PDF
- 生成技术报告
让我先检查环境,然后开始工作。
根据指令,我需要:
- 检查 xelatex –version 和 docker –version
- 如果都没有,停止并询问用户
- 提取 ARXIV_ID=2602.02276
- 下载并提取源码
- 收集论文上下文(标题、摘要、结构、关键术语)
- 翻译文件(跳过附录)
- 审查翻译
- 添加中文支持
- 编译 PDF
- 生成技术报告
让我开始执行。我来帮你翻译这篇 arXiv 论文。先检查环境并下载源码。
……
AI 助手会自己去识别章节结构,只翻译要的部分。同时可以让他做一个技术报告,想快速了解论文思路时很有用。
内置翻译规则
项目里有详细的翻译规则(translation_guidelines.md)。什么该翻译(正文、标题、图表标注),什么不该翻译(数学公式、代码块、人名),怎么处理缩写(CNN → 卷积神经网络, CNN),都写清楚了。
这些规则都是来自我的实际使用经验+AI编的,应该能避免一些翻译错误。
并行翻译
一些论文甚至有几百个.tex文件,翻译起来比较麻烦。Skill 先翻译主文件建立术语表,然后使用subagent 并行翻译其他章节文件。尽可能让术语保持一致,速度也快。
质量检查
翻译完了不能直接编译。得先过检查清单(review_checklist.md):文件完整性(图片、样式文件都在),LaTeX 命令拼写(别翻译时改错了命令),CJK 字符冲突(中文字符可能导致编译失败),内容抽查。
都通过了才编译 PDF。
Agent Skills 怎么设计的
声明式工作流
Skill 文件(SKILL.md)描述「做什么」,不是「怎么做」:
1 | ## Step 2: Translate LaTeX Files |
AI 看了这些步骤就知道怎么做了。我只需要提供论文 ID 就够了。
知识封装
Skills 的目录结构:
| Directory | Purpose |
|---|---|
scripts/ | Agents 可以运行的可执行代码 |
references/ | 按需加载的附加文档 |
assets/ | 模板、图片或数据文件等静态资源 |
翻译规则、模板、检查清单都存在 Skill 里(references/ 目录):
1 | skills/arxiv-paper-translator/ |
其他 Skills 可以引用这些文档。
错误处理
Skill 处理了很多边缘情况:
| 问题 | 解决方案 |
|---|---|
下载的文件是单个 .tex 而非压缩包 | 自动重命名并调整目录结构 |
主文件不叫 main.tex | 用 grep 查找包含 \documentclass 的文件 |
| 编译失败,提示编码错误 | 检测文件编码并转换为 UTF-8 |
| 自定义宏与中文字符冲突 | 插入 {} 分隔符避免冲突 |
这些方案来自实际使用中遇到的问题。
灵活的执行环境
支持本地 XeLaTeX(速度快)和 Docker 容器(一致性好)两种方式。AI 助手自动检测环境选择方案。
我在Windows WSL (Ubuntu) 环境里执行的Claude Code,GLM 4.7 能自动提示按需
sudo apt install texlive texlive-lang-chinese,这点给他个好评。
怎么用
安装:
1 | npx skills add yrom/arxiv-paper-translator |
在你的 AI 助手对话中调用(我测过了Claude Code 和 OpenCode):
1 | > /arxiv-paper-translator 翻译 arXiv:2601.20245 为中文 |
为什么 Agent Skills 值得关注
题外话,这个项目是个给AI用的翻译技能📖,但更重要的是理解怎么把人类知识封装成AI可复用的SOP。
类似的场景还有很多:
- Code Review Skill,自动检查规范、漏洞、性能。
- 数据分析Skill, 自动清洗数据、生成报告。
- 系统部署Skill, 自动化 CI/CD、跟踪Building。
- 剪辑视频Skill, 自动分析视频素材、调用ffmpeg剪辑视频。
- PPT 制作Skill, 自动根据文案通过写HTML生成PPT。
每个领域的经验都能封装成 Skills。这就是为什么OpenClaw (曾用名ClawdBot/MoltBot)这么好用和🔥的关键因素之一。
几点体会
结构化文档比长提示词好维护
把知识拆成模块化文档(guidelines.md, checklist.md)比写一大段单一Prompt文件容易维护。要改规则直接改对应的Markdown,不用重写整个Prompt文件。
Skill 需要在实际使用中打磨
这个项目的错误处理方案来自翻译论文时踩的坑。边用边让AI自己完善,没有实践很难想全边界case,毕竟 TeX 是个历史悠久又复杂的系统。
声明式写法给 AI 更多自主空间
不要写「先执行 A,然后执行 B」。写「需要完成 X 任务,参考 Y 文档」。AI 自己判断怎么做。当然,对于能力的弱的LLM,还是需要写得详细一些。
用高级的模型
理解力不够的模型,执行时容易出错,不要浪费时间在低级模型上。
我这里有个小技巧:用高级模型写SKILL,然后用低级模型执行。再让低级模型根据执行结果反馈给高级模型更新SKILL,如此反复,不断完善。
Coding Agent + Skills = 垂直领域 Agent
体验下来,类似Claude Code 这样的比较通才的 Coding Agent,结合上领域特定的Skill,效果还是不错的,比如这个翻译Skill、还有remotion-video Skill, videocut SKill。
我认为:这种通用Coding Agent + 垂直领域Skill 的组合,未来一定会成为主流。某种意义上讲类似“AI PPT”这种垂直类 Agent 会越来越少,但领域类Agent Skills 会越来越多。
The new paradigm
Code is all you need 参考阅读Building agents with Skills: Equipping agents for specialized work
总结
如果你有重复性的多步骤工作流,可以试试封装成 Skill。把专业知识和流程文档化,交给有能力的 AI Agent 执行。
欢迎来到 AI 时代。
Code is cheap, show me the prompts.
The Prompt is Agent SKILLs.
相关链接
- 项目地址:https://github.com/yrom/arxiv-paper-translator
- Agent Skills 标准:https://agentskills.io/
- 使用示例:
- 完整翻译:
claude -p "/arxiv-paper-translator 翻译 arXiv:2601.20245 为中文" - 部分翻译:
claude -p "翻译 arxiv:2602.02276,跳过附录、实验数据部分" - 翻译 + 总结:
claude -p "/arxiv-paper-translator 翻译arxiv:2602.02276并整理核心观点输出博客"
- 完整翻译:
有问题或建议可以在 GitHub Issues 讨论。
References
- https://platform.claude.com/docs/en/agents-and-tools/agent-skills/best-practices
- https://resources.anthropic.com/hubfs/The-Complete-Guide-to-Building-Skill-for-Claude.pdf?hsLang=en
- https://github.com/CTeX-org/lshort-zh-cn
- https://claude.com/blog/building-agents-with-skills-equipping-agents-for-specialized-work