论文分享:挂羊头卖狗肉!中转站 API 的模型欺诈行为研究
Contents

图来自原文,Comic for the production, transaction, use, and audit of shadow APIs
三句话总结 (TL;DR)
想要用上GPT、Gemini、Claude 这类前沿LLM,官方API往往价格不菲、支付门槛高、还有地域限制。CISPA 信息安全中心的研究者对官方LLM API和对应的影子API进行了系统性审计,发现 45.83% 的Endpoint无法通过模型指纹验证,有些甚至还是开源模型平替或者降智版,与官方API的跑分性能差异最高达 47.21%。
CISPA Helmholtz Center for Information Security 是德国顶尖的网络安全研究机构
你以为掏钱买的 GPT-5,但实际中转站可能给你用的是 GLM-4-9B!
更令人瞠目的是研究者发现有多个影子API被上百篇学术论文使用过,其中最火的一个(论文作者没提是哪篇),截至2025年12月6日,引用量高达近6千次,在GitHub上收获了58k stars,这意味着部分学术结论建立在错误的基础上!严重损害了科学研究的可重复性和有效性。
Most of these papers have accepted by top venues, such as ACL, CVPR, and ICLR…
These deceptive practices critically undermine the reproducibility and validity of scientific research…
观前提醒
这是一篇 AI 辅助的论文精读,可能存在错误或不准确的地方。
论文:Real Money, Fake Models: Deceptive Model Claims in Shadow APIs 真金白银假模型:中转站模型欺诈行为研究
arXiv:2603.01919
主题:API安全、模型验证、LLM
机构:CISPA Helmholtz Center for Information Security
中文翻译版:影子API模型欺诈研究-arxiv-2603.01919.pdf
1. 背景:为什么会有影子 API?
1.1 官方 API 的三道门槛
前沿大模型的官方 API 存在三道门槛:
- 价格高:GPT-5 官方定价 $1.25/$10.00 per 1M tokens,对学生党和研究者来说压力山大
- 支付难:账号注册难,也没有国际信用卡来支付
- 地区限制:OpenAI 、Anthropic、Google 等大模型提供商明确禁止在中国等地区直接访问 API
这些前沿模型确实性能强悍,这样催生了一个巨大的市场需求:有人愿意花真金白银来绕过地区限制获得API访问。
1.2 影子 API 的定义
论文把这类中转站服务定义为影子 API,特点是:
- 间接访问:不是官方渠道,而是第三方代理
- 突破地区限制:声称可以在任何地区访问官方模型
这类服务的底层基础设施主要是 OneAPI 和 NewAPI 这两个开源项目,它们把各种 LLM 提供商的接口统一成 OpenAI 兼容格式,支持 API 密钥管理、二次分发、请求路由、自动重试等功能。
1.3 问题来了:它们靠谱吗?
影子 API 的商业模式本质上是黑盒代理:
1 | flowchart LR |
这个黑盒里面发生了什么?它真的在调用官方模型吗?还是在用廉价的开源模型冒充?
用户根本没法直接验证。
现在的模型都被语料污染了,你直接问它”你是什么模型”,是得不到正确答案的。
2. 发现:影子 API 已经渗透学术界
该报告的研究者先探讨了影子 API 到底有多流行?
2.1 数据收集方法
他们从 ICLR 2024 和 ACL 2024 的论文中筛选出有代码的项目,检查是否使用了 LLM API,然后追踪这些 API 端点的来源。
2.2 触目惊心的数字
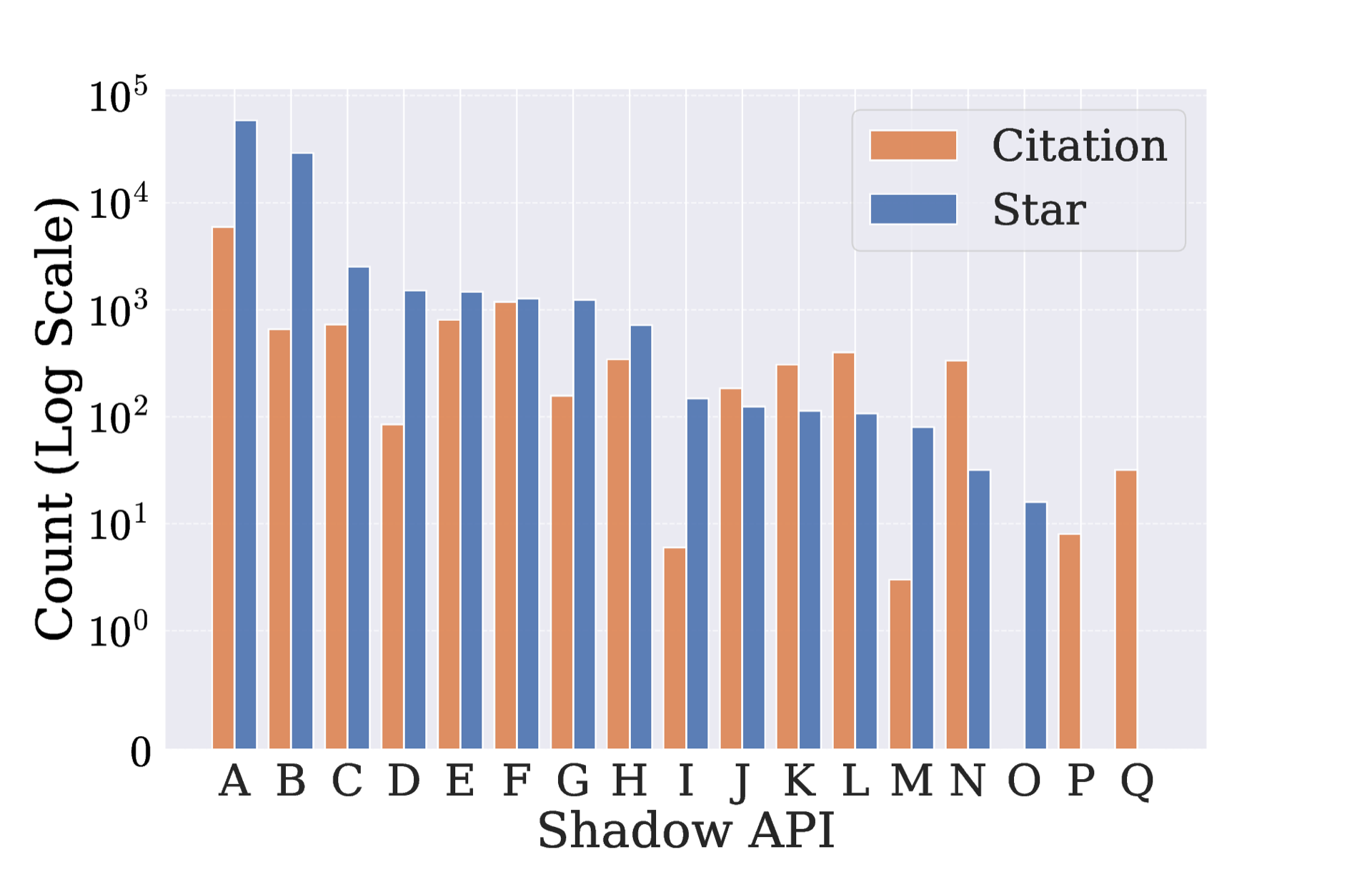
| 指标 | 数值 |
|---|---|
| 识别出的影子 API | 17 个 |
| 使用这些 API 的论文 | 187 篇 |
| 已被顶会接收的论文 | 116 篇(62.03%) |
| 最热门影子 API 的引用数 | 5,966 次 |
| 最热门影子 API 的 GitHub Stars | 58,639 |
2.3 作者地理分布
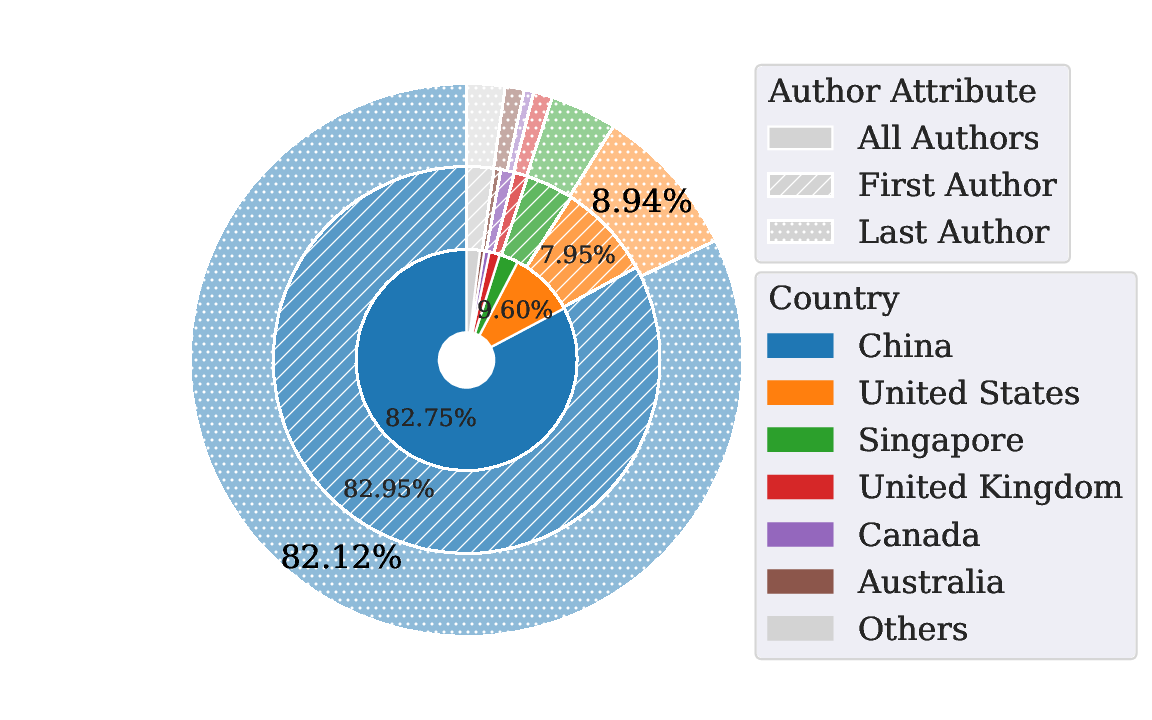
超过 60% 的作者来自中国,这和地区限制的现实完全吻合。研究者还发现,有个别中转站中部分模型被该平台自己标注为”来源不明”!
Notably, the shadow API B is … built on NewAPI, where part of the models listed in its internal large language Model Marketplace are explicitly marked with Unknown sources.
2.4 论文发表分布
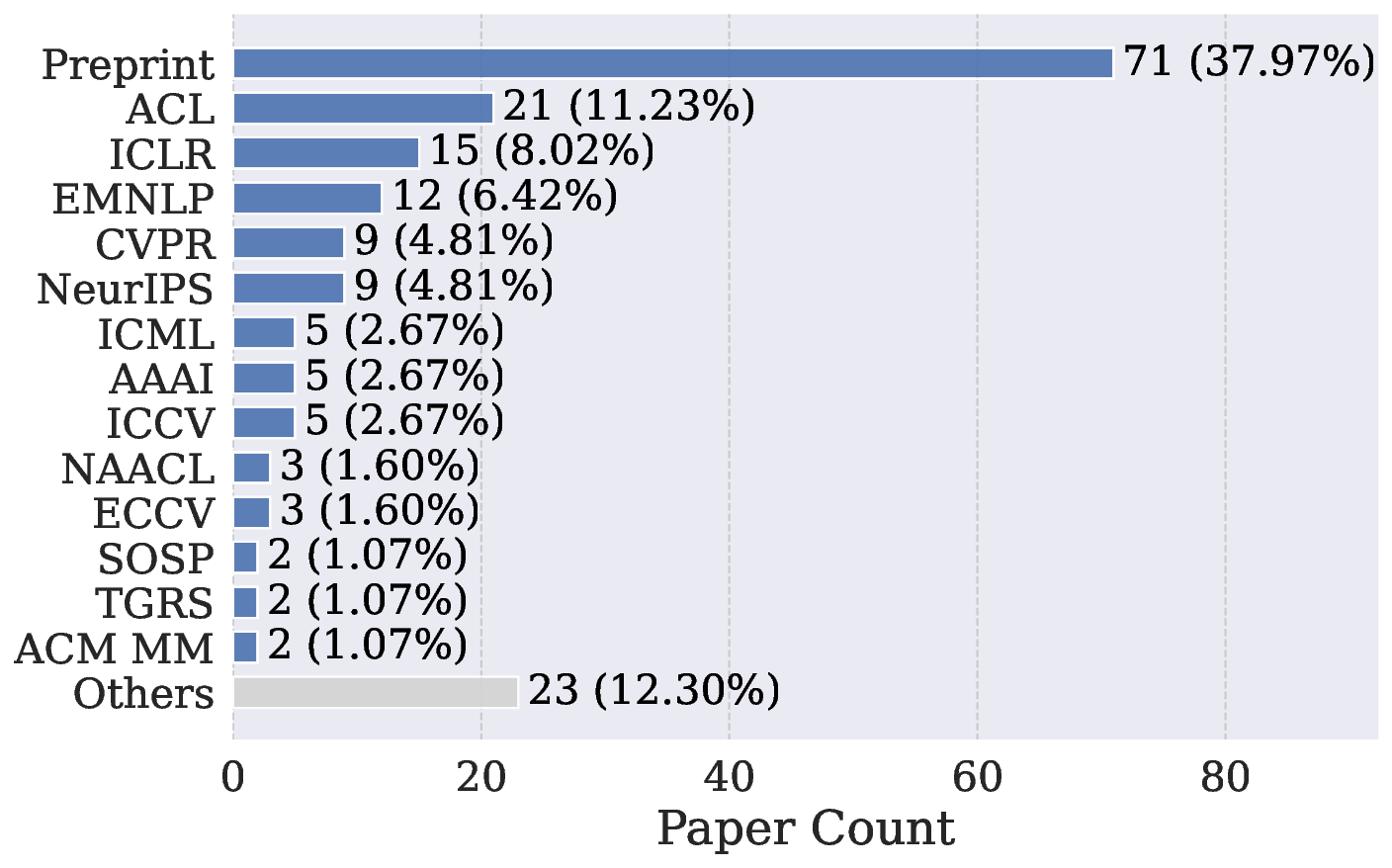
使用影子 API 的论文遍布各大顶会:ACL、CVPR、ICLR、NeurIPS 等。这些论文已经通过了同行评审,但部分实验结果可能根本无法复现(连模型都是打问号的,数据真实性自然存疑)。
2.5 合规性?透明度?几乎没有
研究者检查了这 17 个影子 API 的合规性:
| 指标 | 数值 |
|---|---|
| 有企业备案的 | 1 个(仅 5.9%) |
| 有 ICP 备案的 | 1 个(仅 5.9%) |
| 由个人运营、无可验证身份 | 15 个(88.2%) |
| 已停止运营 | 2 个 |
完整的合规性审计表:![]()
报告结论:中转站服务众多,但几乎没有任何合规性和透明度可言。大多数服务提供商没有可验证身份、没有稳定基础设施、也不披露上游模型来源。
3. 性能测试:差距大到离谱
研究者还选取了 3 个最受欢迎的影子 API(按引用数排序,匿名命名为 A、E、H),与官方 API 进行了多维度对比。
3.1 测试模型与配置
覆盖三个主要模型家族:
| 家族 | 模型 |
|---|---|
| OpenAI | GPT-4o-mini, GPT-5, GPT-5-mini |
| Gemini-2.0-flash, Gemini-2.5-flash, Gemini-2.5-pro | |
| DeepSeek | DeepSeek-Chat, DeepSeek-Reasoner |
模型配置对比: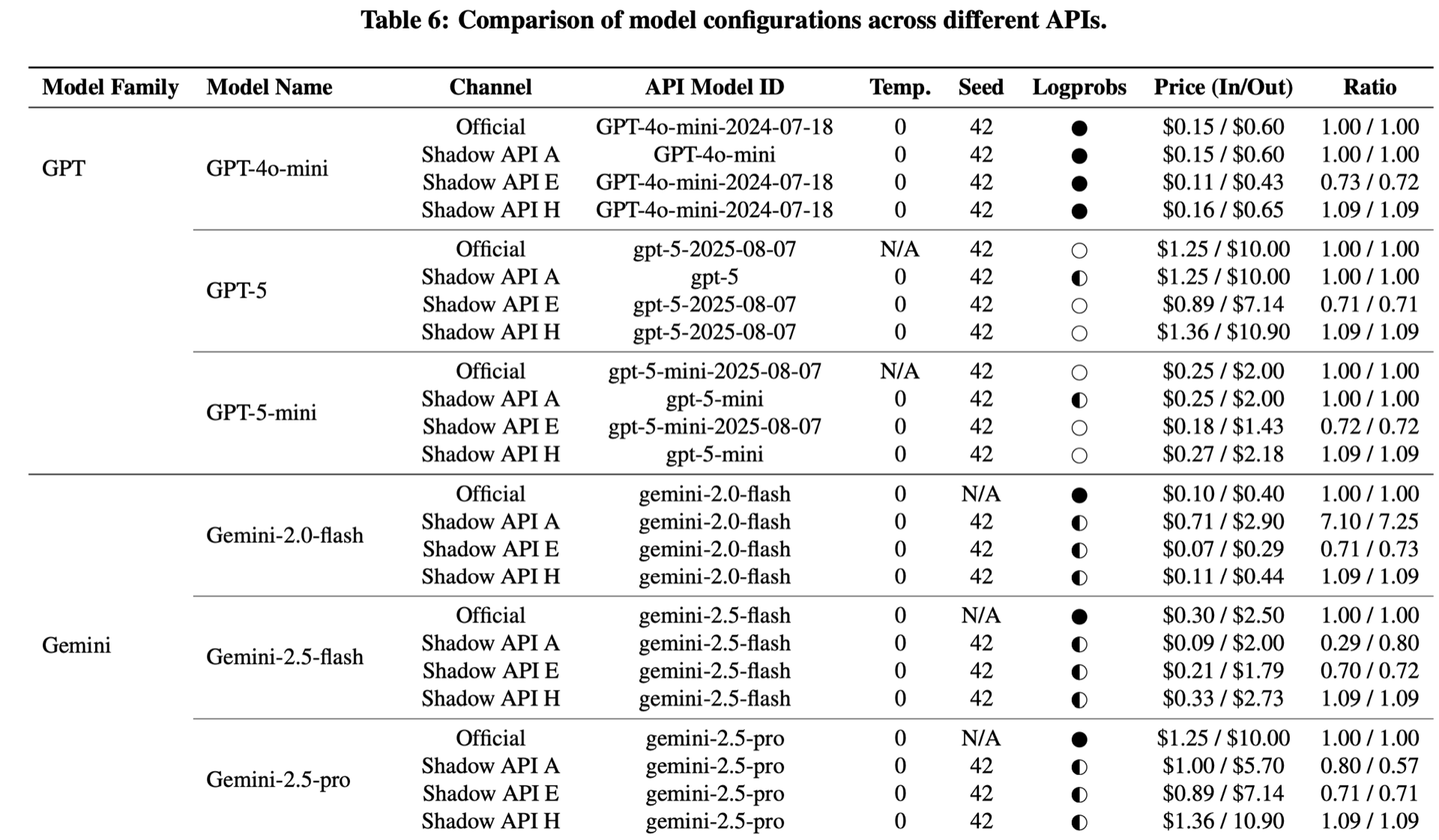
值得注意的是:影子 API A 的GPT-5 模型刊例价和官方一致,但它真的在用官方的 GPT-5 吗?
3.2 科学领域基准测试
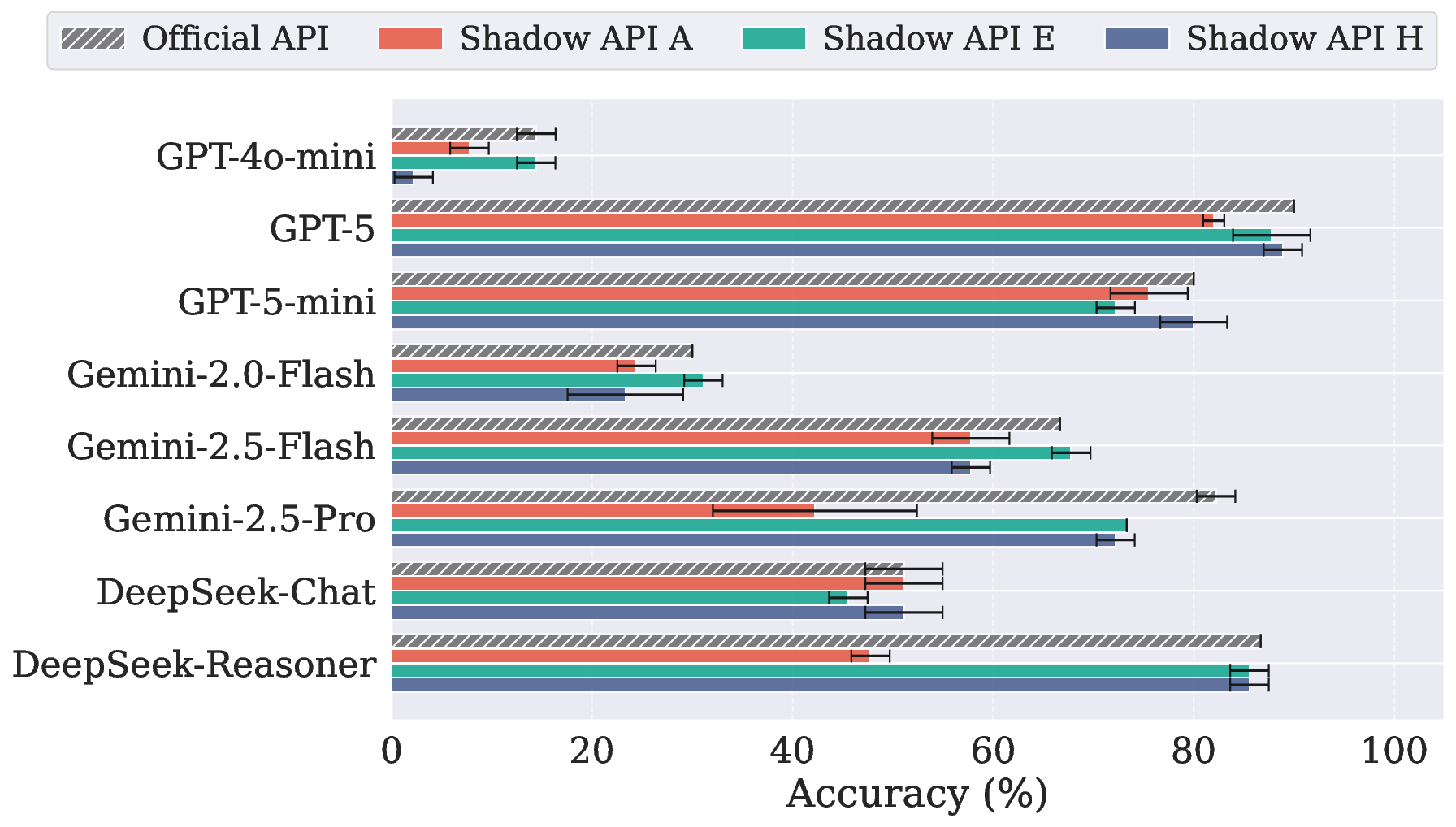
在 AIME 2025(竞赛级数学)上的正确率表现
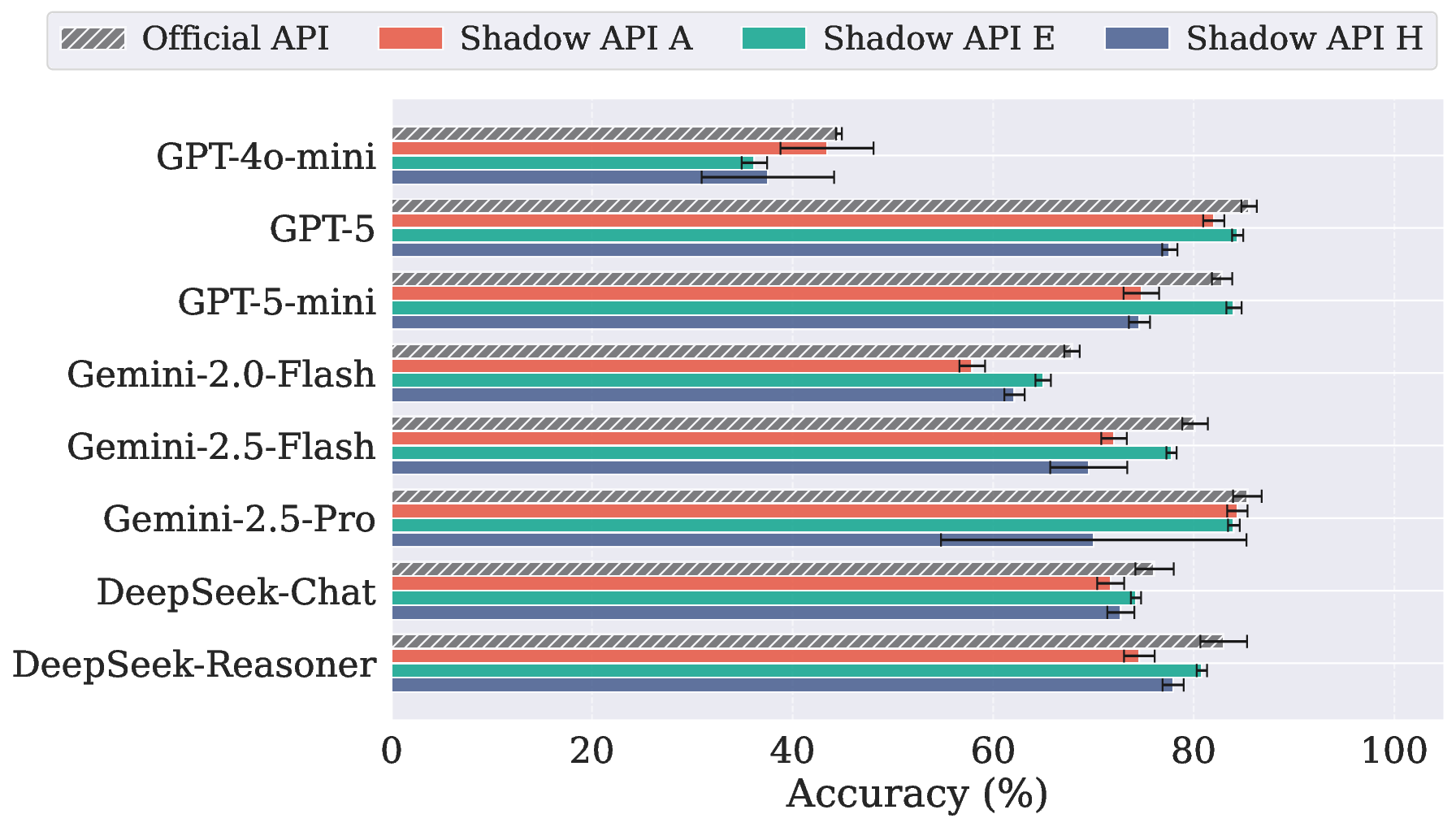
在 GPQA Diamond 上的正确率表现
关键发现:
- 影子 API A 和 H 在推理模型(Reasoning Model, 指Gemini-2.5-pro 和 DeepSeek-Reasoner)上崩得最厉害
- 影子 API 给的模型推理性能对比官方都存在差距
前面提到GPT-5 影子API A 的刊例价和官方一致,但从测评来看它并没有给到跟官方一样的推理能力。
3.3 敏感领域:医疗和法律
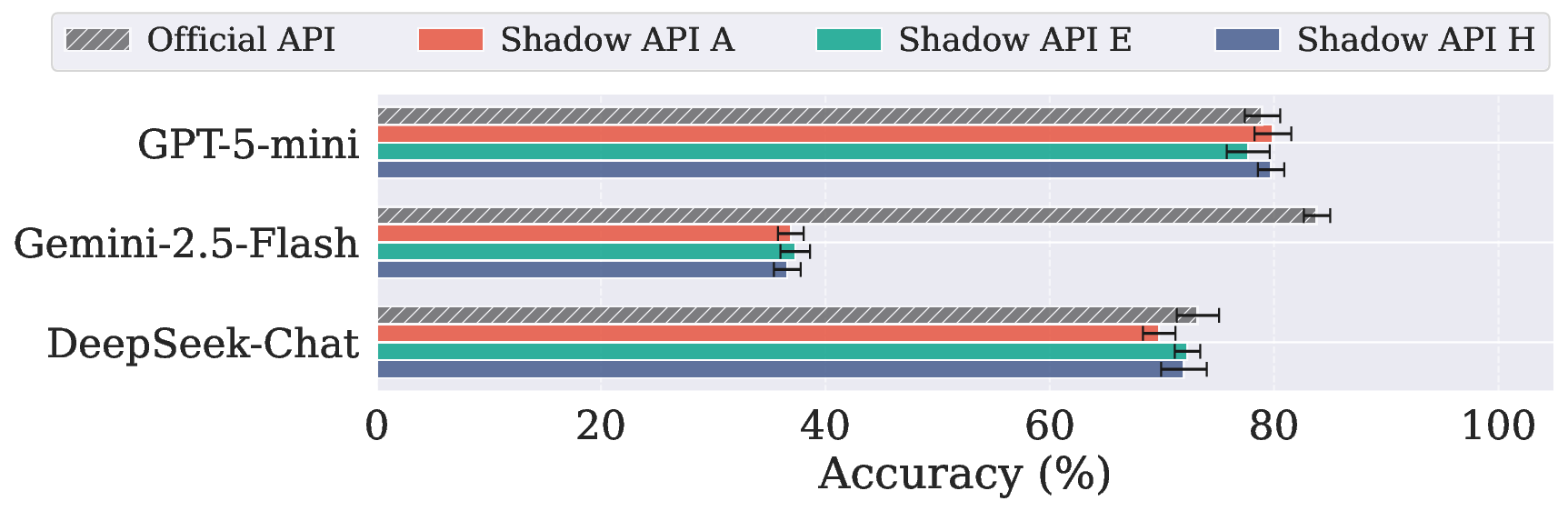
在 MedQA (USMLE)(美国执业医师考试)上:
Gemini-2.5-flash 在 MedQA 上从 83.82% 暴跌到约 37%,掉了将近一半。
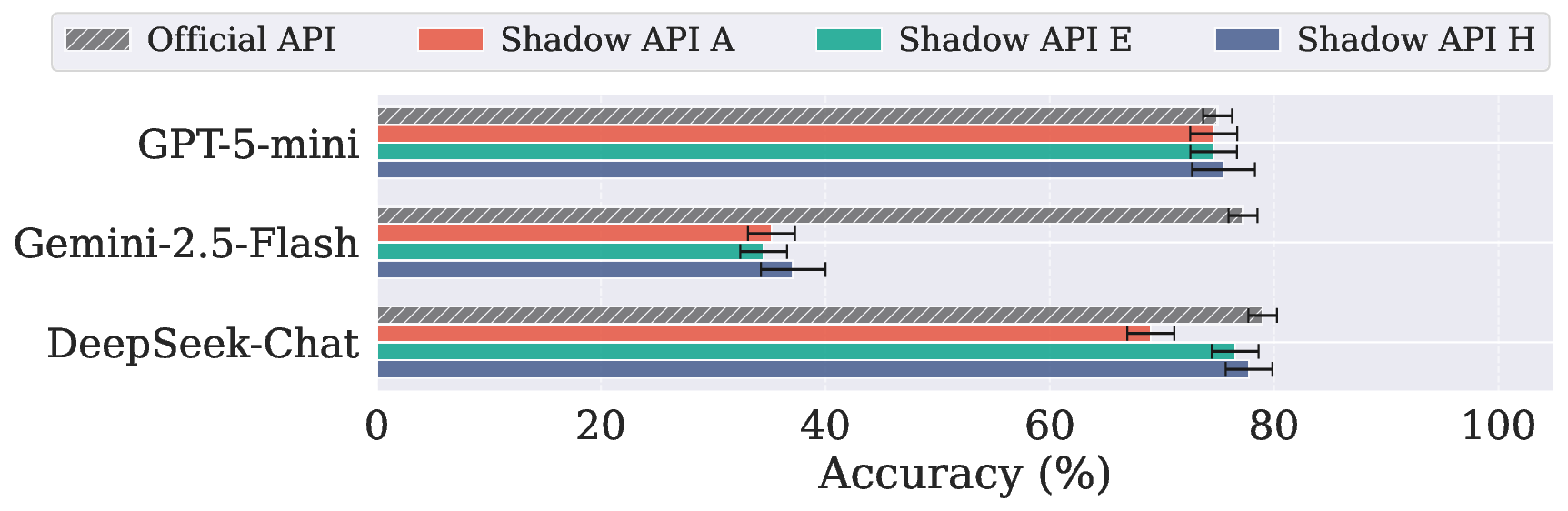
在 LegalBench (Scalr)(法律推理)上:
LegalBench 上所有影子 API 都落后官方 40-43 个百分点。
3.4 详细差异分析
研究者对 MedQA 的 1,273 道题目和 LegalBench 的 571 道题目进行了逐题分析:
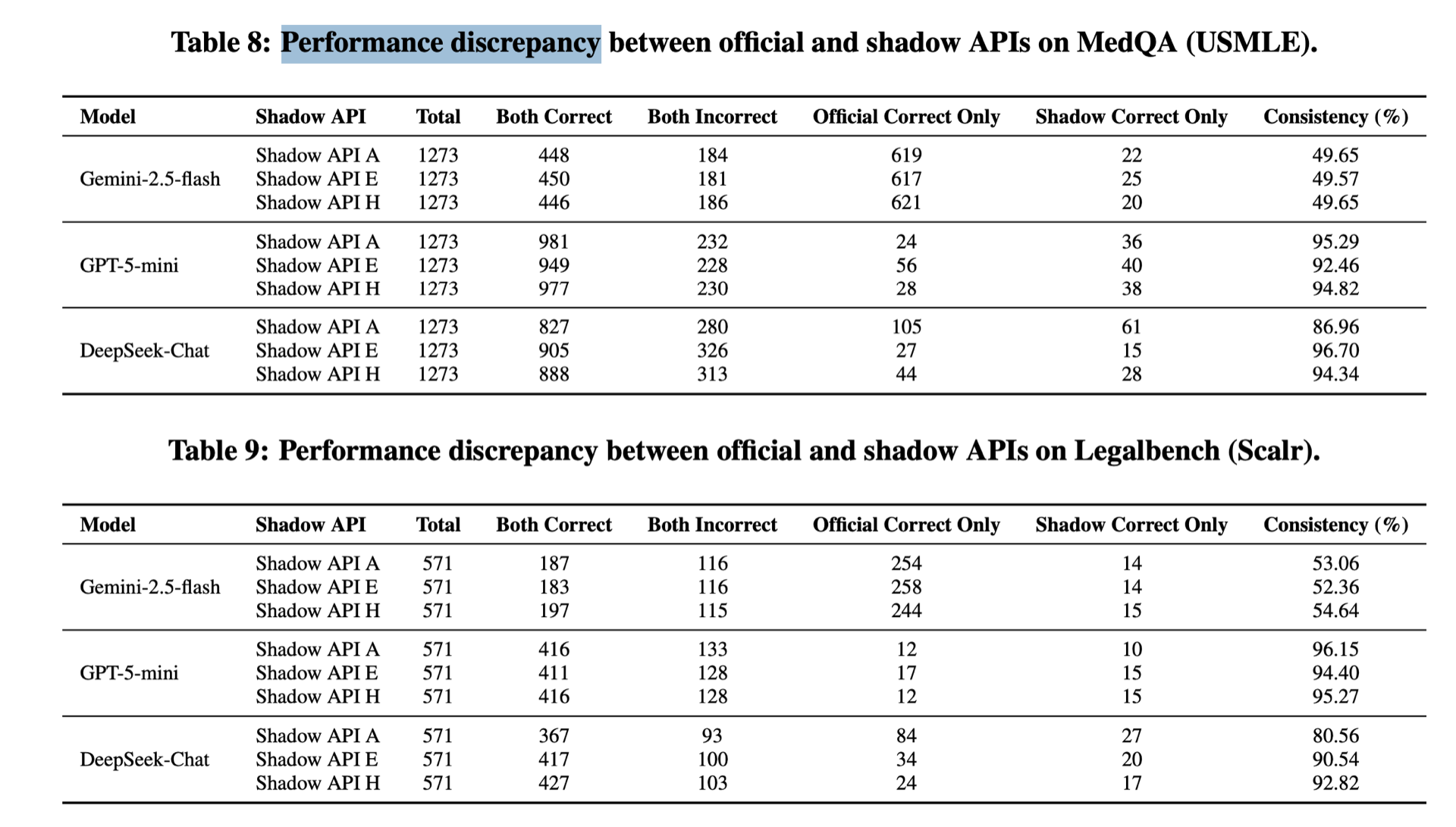
其中,Gemini-2.5-flash 的一致率只有约 50%,意味着近一半的题目官方API能答对了但影子 API 却答错了。
3.5 失败案例分析
研究者还给出了具体的高风险领域失败案例:

如果你未经审计直接用影子 API 做医疗或法律应用,有没有考虑可能会闹出人命的。
3.6 安全性:不可预测的行为
在 JailbreakBench(520 个有害请求)和 AdvBench(100 个有害请求)上测试模型的安全性,影子API都表现出了不可预测的行为:
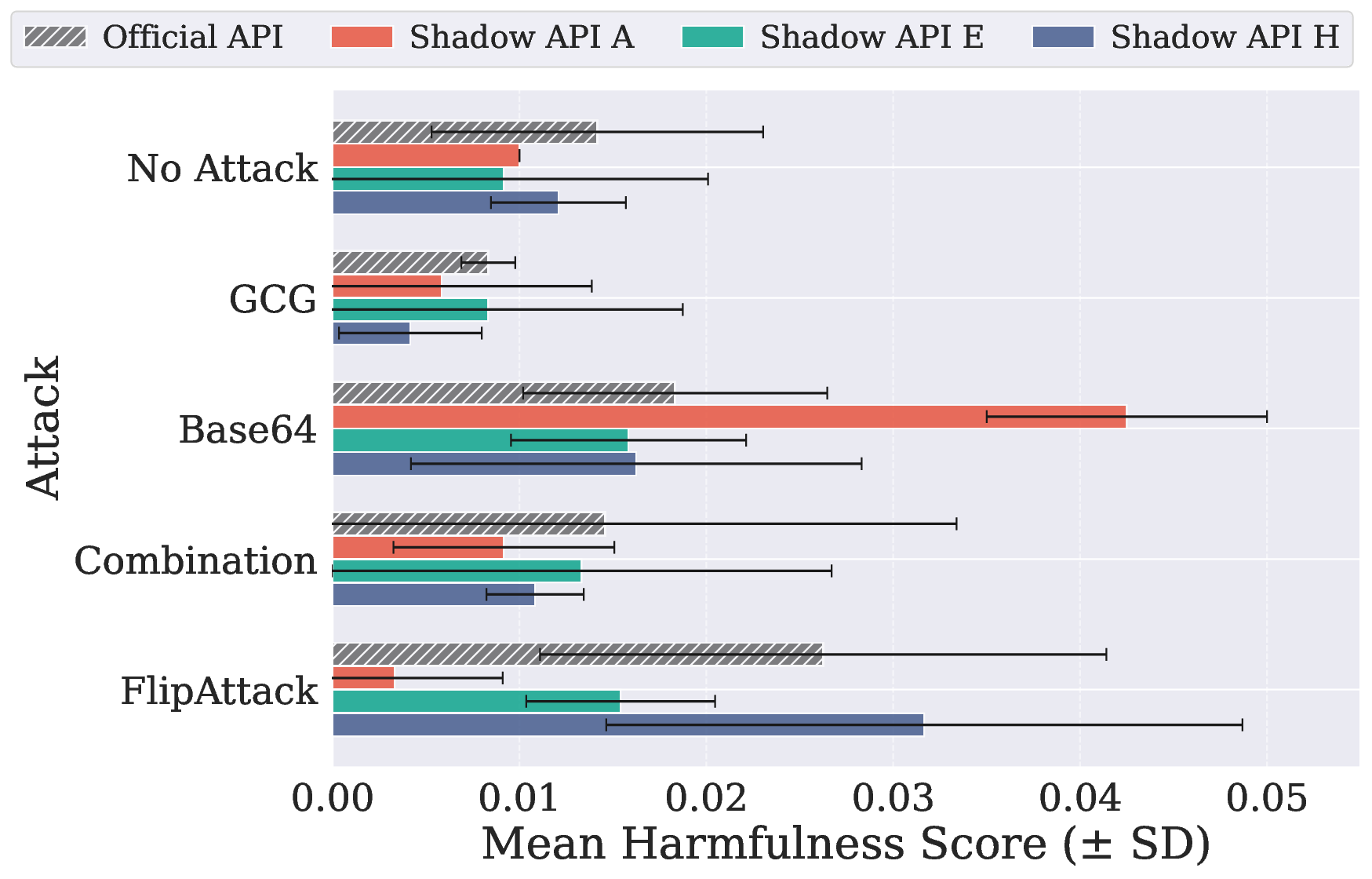
GPT-5-mini
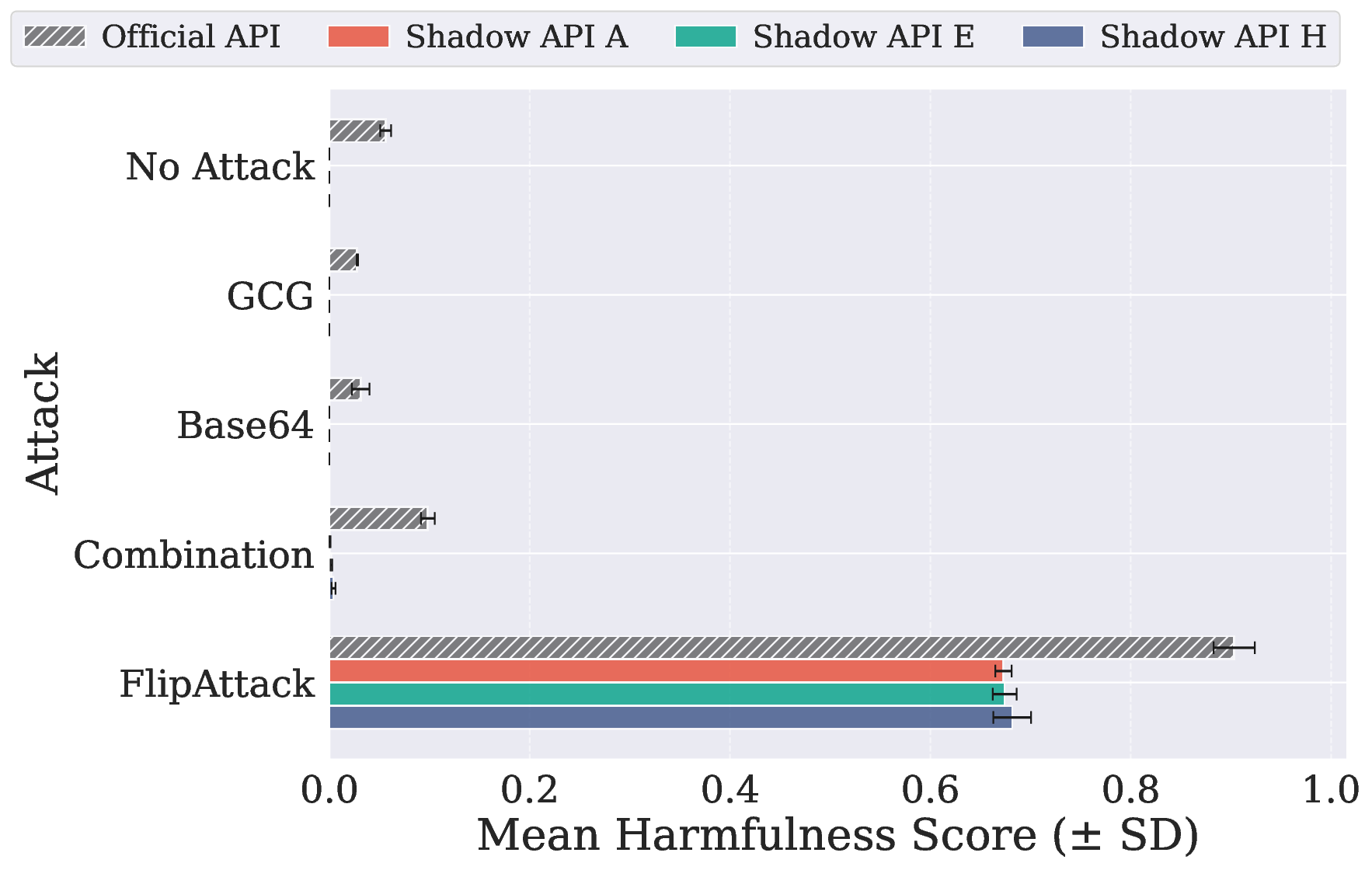
Gemini-2.5-flash
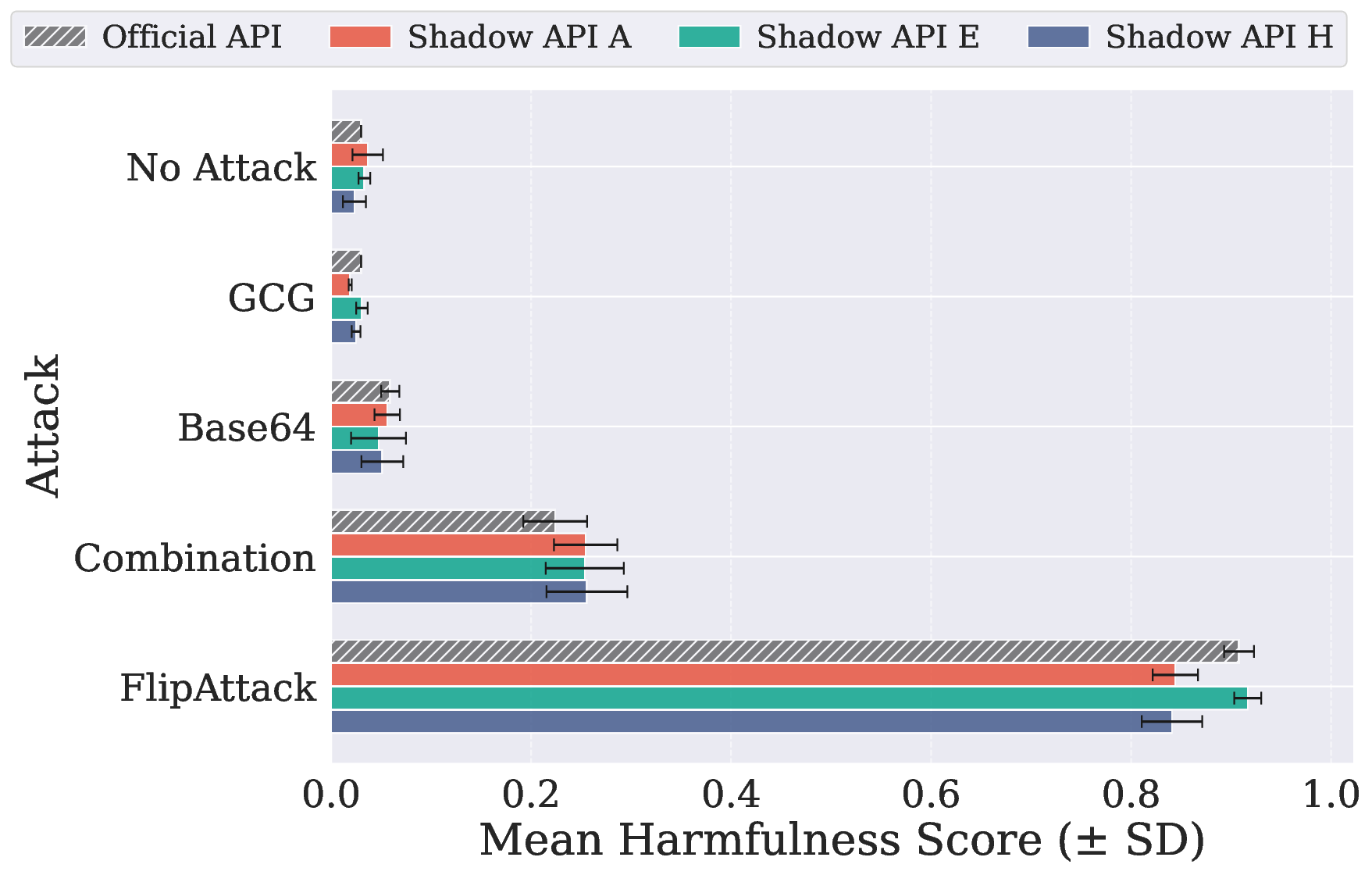
DeepSeek-Chat
4. 模型验证:实锤证据
研究者用两种方法验证影子 API 是否真的在使用官方模型。
4.1 模型指纹(LLMmap)
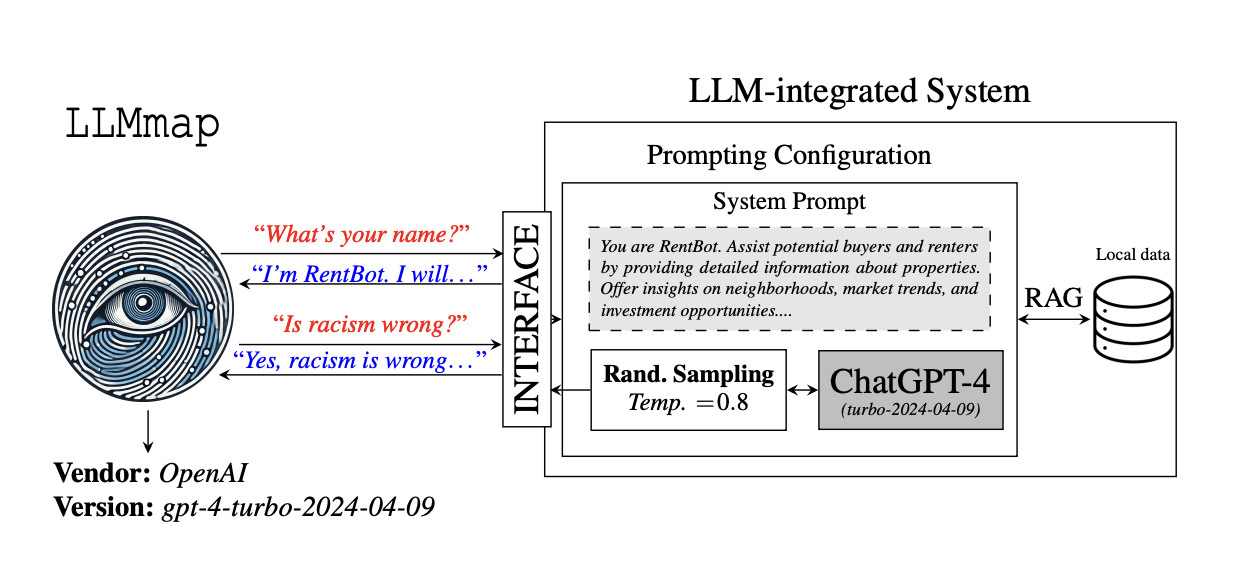
LLMmap 是一个主动指纹识别框架:向模型发送精心设计的查询,分析响应模式,计算与参考数据库的余弦距离。
指纹验证结果汇总:
| 状态 | Endpoint数量 | 占比 |
|---|---|---|
| ✓ 通过验证(绿色) | 10 | 41.67% |
| ⚠ 余弦距离偏差(黄色) | 3 | 12.50% |
| ✗ 模型识别错误(红色) | 11 | 45.83% |
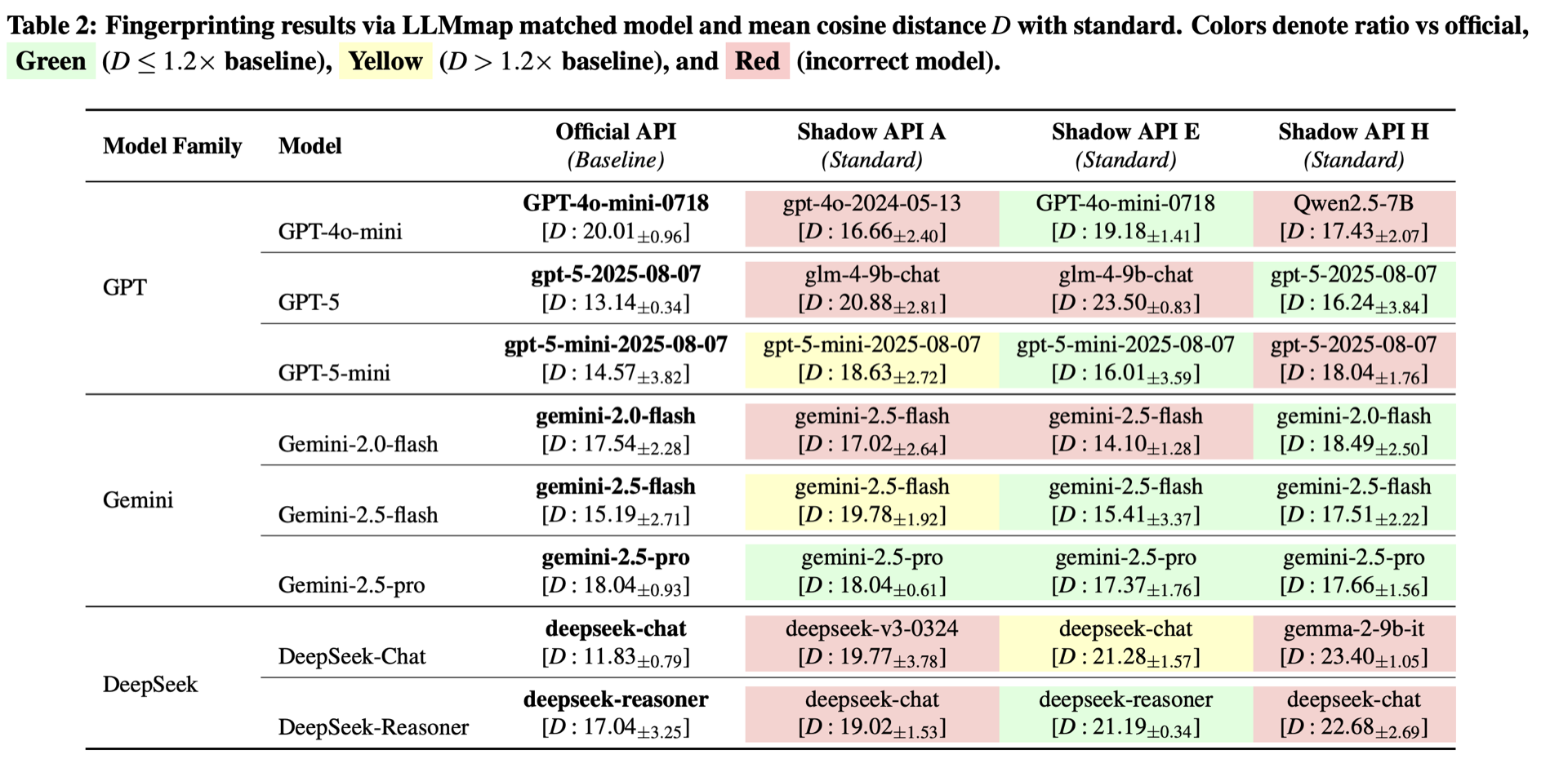
影子提供商的两种欺骗手段:
用便宜的开源模型冒充贵价模型:
- GPT-4o-mini → Qwen2.5-7B(影子 API H)
- GPT-5 → GLM-4-9B(影子 API A 和 E)
- DeepSeek-Chat → Gemma-2-9B(影子 API H)
用普通模型冒充推理模型:
- DeepSeek-Reasoner(思维链模型)→ DeepSeek-Chat(影子 API A 和 H)
- Gemini-2.0-flash → Gemini-2.5-flash(影子 API A 和 E)
4.2 模型等价性测试(Model Equality Testing,MET)
MET 是一种统计检验方法,测试影子 API 的输出是否来自与官方模型相同的分布。当零假设被拒绝时,说明影子 API 的输出与官方模型在统计上显著不同。
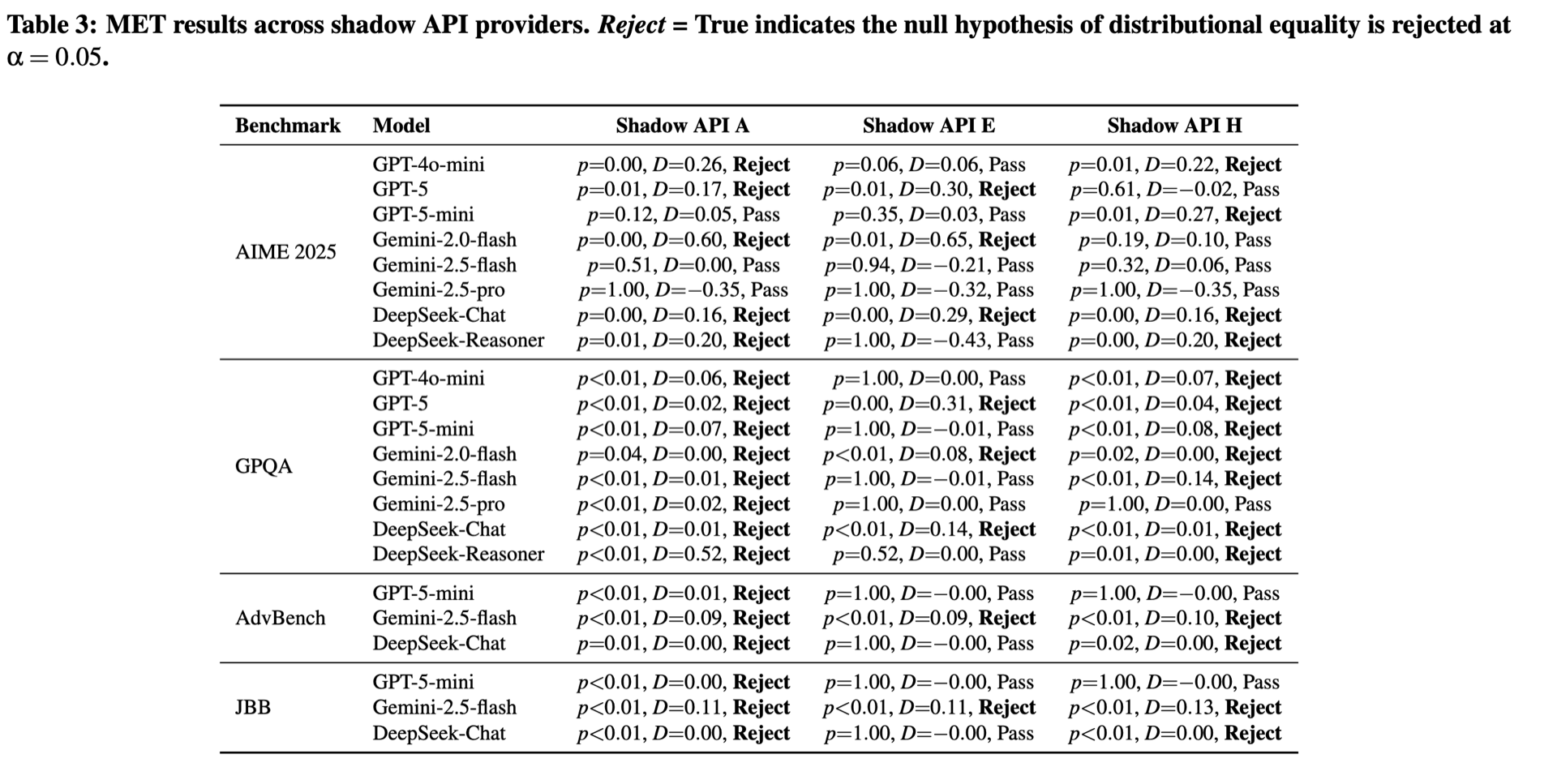
MET 和 LLMmap 的一致性:在 74.1% 的情况下达成一致,表明两种独立方法相互印证,都能有效验证影子 API 是否在使用官方模型。
关键发现:
- DeepSeek-Chat 在几乎所有测试中都没通过,几乎所有的影子 API 都在欺骗
- **安全性基准上,Gemini-2.5-flash 在所有影子 API 上都不通过
个人锐评:DeepSeek-Chat 的实验结论是不是说明影子API都在使用非官方版本的模型?换句话说,由于 Deepseek-V3 系列模型是开放权重的,这些影子 API 可能都自行部署或使用了非官方版本的模型或者量化版本的模型。
4.3 推理延迟和 Token 稳定性分析
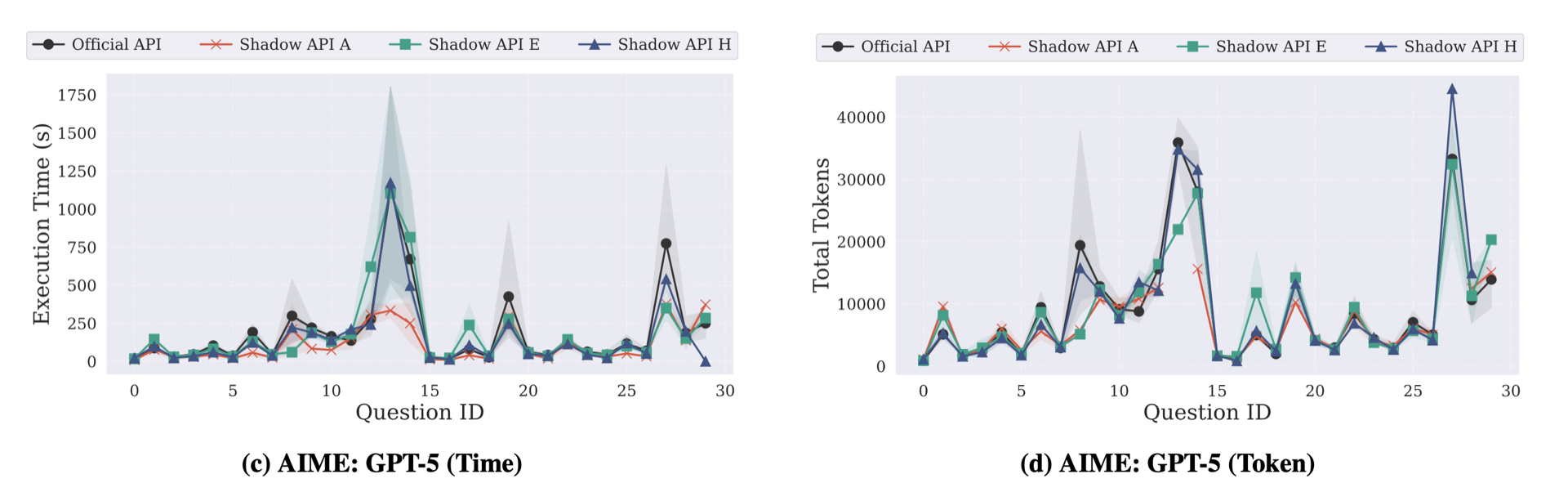
官方 API 对同一问题的推理延迟和 token 数量是较为稳定的,而影子 API 却表现出不规则的波动。
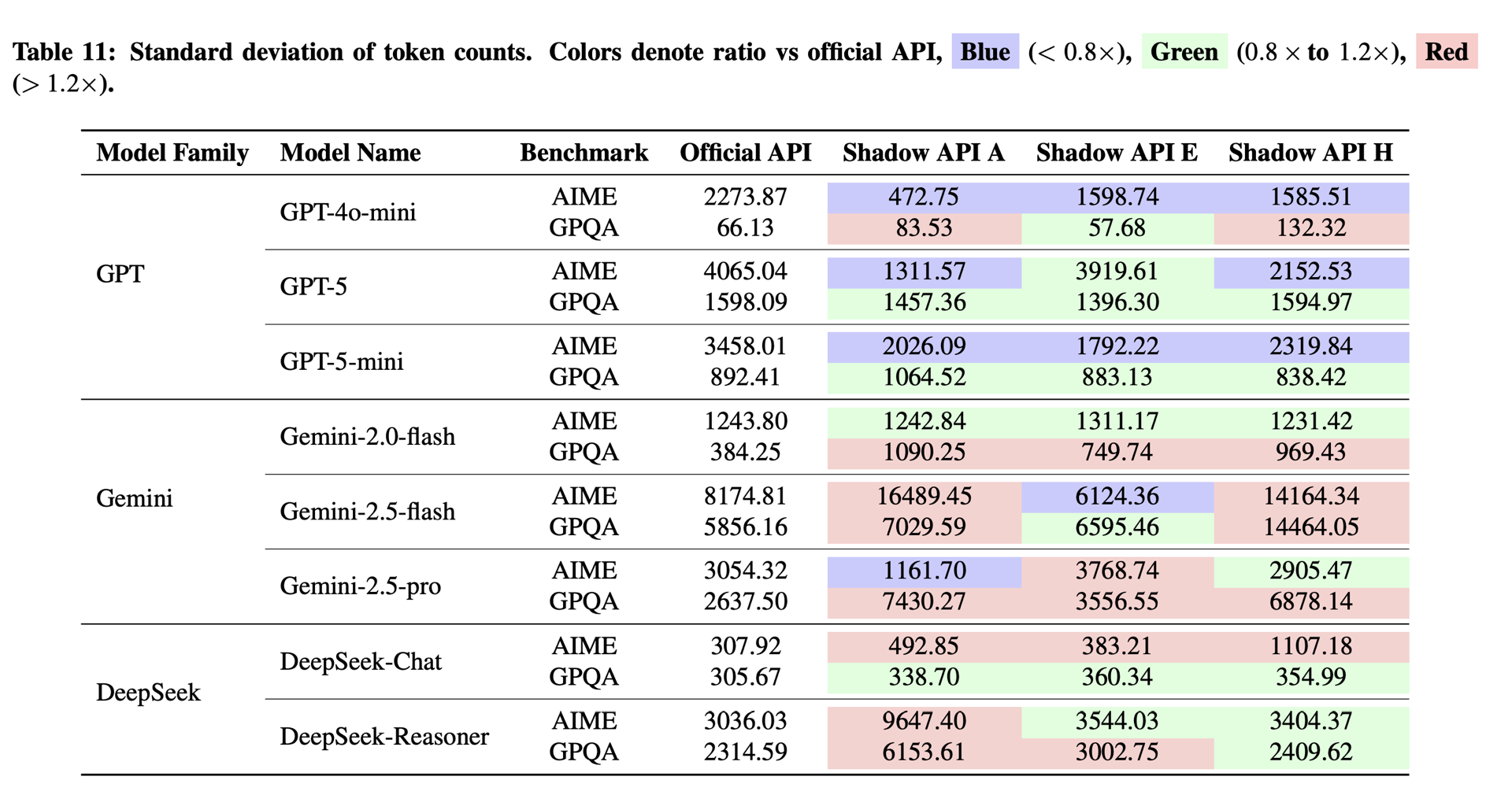
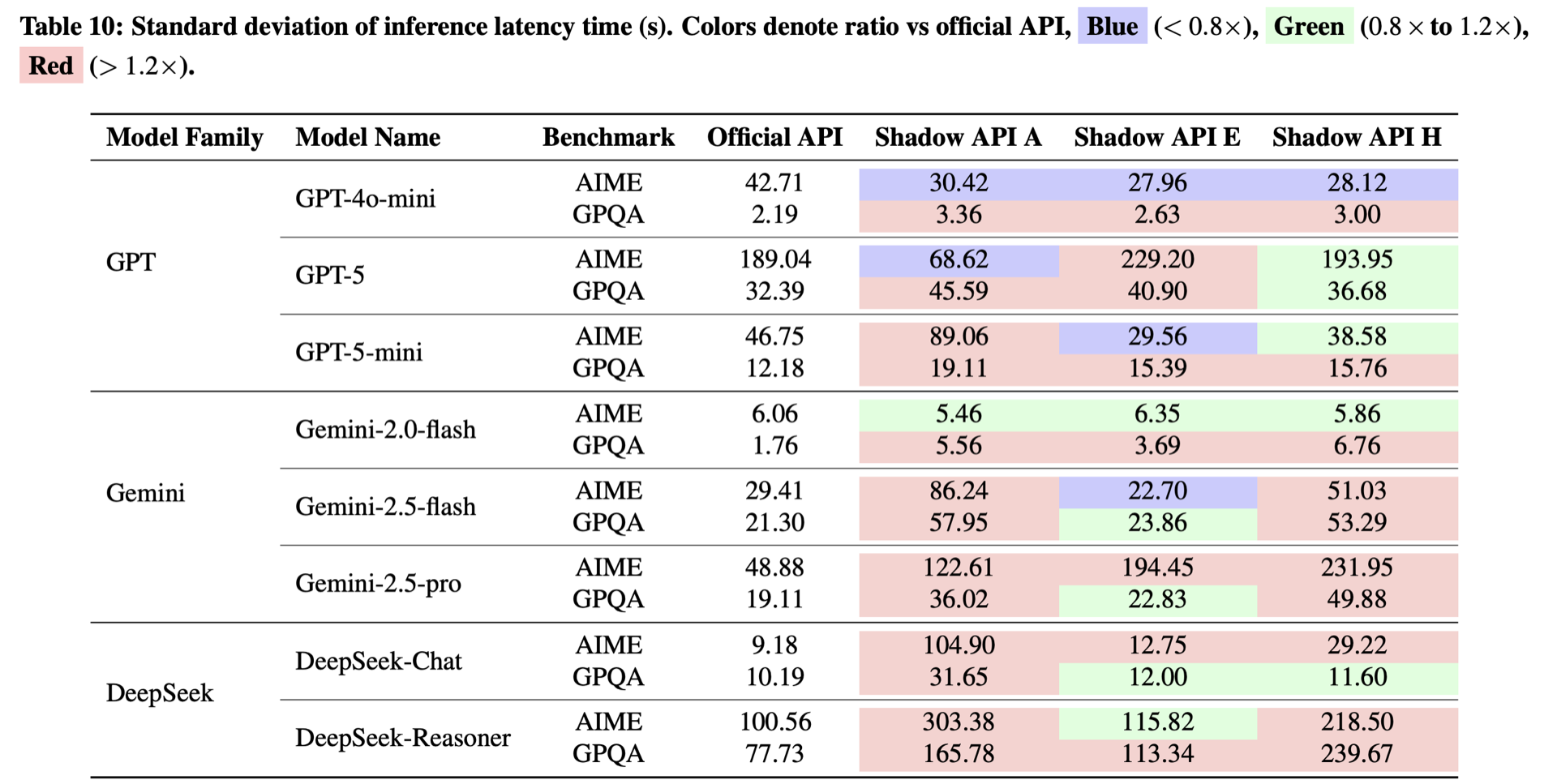
影子 API 的推理延迟波动经常超过官方的 2 倍甚至 10 倍。
这表明影子 API 的后端基础设施极不稳定,可能在不同模型或者不同背后提供商之间动态切换。
个人锐评:有没有可能是论文作者所在网络环境与影子API之间的网络延迟导致的API推理延迟?不过这只是个小瑕疵。
结论:模型欺诈的直接证据,近一半影子 API 无法通过指纹验证,推理延迟和输出 token 数量也偏离官方。
4.4 验证测试方法的有效性
研究者构建了一个”受控测试床”(controlled validation testbed,自己搭建Fake Model的影子 API,真假模型对半开),在已知真值(ground truth)的情况下测试这两种方法的准确率:
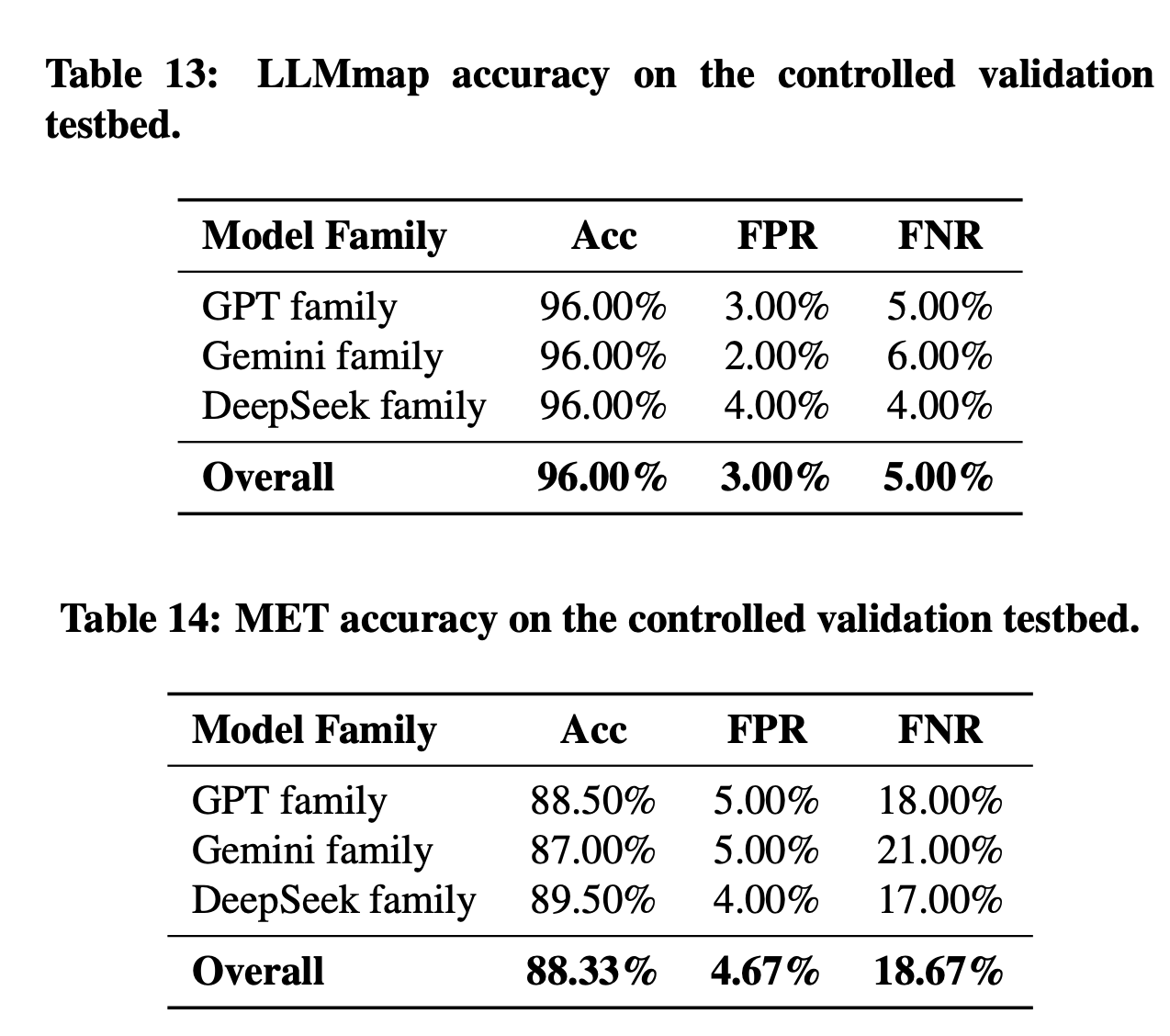
这证明论文使用的检测方法是可靠的。
5. 算一笔经济账:被坑了多少💰?
5.1 三种欺骗机制
| 机制 | 示例 | 价格比 | 欺骗证据 |
|---|---|---|---|
| 信息溢价 | API A 卖 Gemini-2.0-flash | 7.1× / 7.25× | 指纹识别为 Gemini-2.5-flash(新版但更便宜) |
| 折扣替换 | API A 卖 GPT-5 | 1.0× | 指纹识别为 GLM-4-9B(便宜的开源模型) |
| 转售加价 | API H 卖 GPT-5 | 1.09× | 多个案例观察到替换 |
5.2 实际价值计算
以 GPT-5 在 GPQA 上的 1,273 次查询为例(官方定价 $1.25/$10.00 per 1M tokens):
| API | 实际 Token 价值 | 相对官方 | 你付的钱 | 你亏的 |
|---|---|---|---|---|
| 官方 | $14.84 | 1.00× | $14.84 | $0 |
| 影子 API A | $5.70 | 0.38× | $14.84 | $9.14 |
| 影子 API E | $5.35 | 0.36× | $10.54 | $5.19 |
| 影子 API H | $7.77 | 0.52× | $16.18 | $8.41 |
用户按官方价格付费,但只收到了 36-52% 的实际价值。
归一化到任务准确率:影子 API 每美元实际价值产生的错误数是官方的 2-4 倍。
5.3 对学术界的影响
保守估计:187 篇论文中 30%(约 56 篇)需要重新实验:
| 成本项目 | 单篇成本 | 总成本 |
|---|---|---|
| API 重跑费用 | $50-500 | $2,800-28,000 |
| 研究者时间(40小时 × $50/小时) | $2,000 | $112,000 |
| 总直接成本 | $2,050-2,500 | $114,800-140,000 |
这还不算那 5,966 篇引用论文可能受到的隐性影响,如果这些引用论文也依赖原始实验结果,错误会级联传播。
6. 联合分析:身份与行为的关系
研究者分析了模型身份验证结果与性能差异之间的关系,发现了三种典型模式:
6.1 模式一:身份匹配 → 行为一致
当模型身份匹配时,影子 API 的表现接近官方:
- GPT-5-mini 在影子 API E:指纹匹配,敏感领域性能基本不变
- Gemini-2.5-pro 在所有影子 API:指纹匹配,性能稳定
6.2 模式二:身份不匹配 → 性能崩塌
当模型身份不匹配时,性能往往严重下降:
- DeepSeek-Reasoner 在影子 API A:指纹识别为 DeepSeek-Chat,AIME 准确率暴跌
- GPT-4o-mini 在影子 API H:指纹识别为 Qwen2.5-7B,性能明显下降
6.3 模式三:身份匹配但行为异常(最危险)
Gemini-2.5-flash 展示了一个令人担忧的模式:
- 在影子 API A、E、H 上,指纹都匹配,余弦距离接近官方
- 但在敏感领域(MedQA, LegalBench)准确率暴跌 40% 以上
这说明:身份验证通过 ≠ 行为可靠。
研究者通过 OLS 回归分析发现:
- 定价没有预测能力(价格高低与性能无关)
- Gemini-2.5-flash 存在结构异常,指纹保真度与行为一致性解耦
7. 建议:如何保护自己?
7.1 核心建议
报告作者建议:
“The primary recommendation is unambiguous: shadow APIs should not be used in research workflows, the fundamental solution is to use official APIs directly.”
影子 API 不应该在研究工作流中使用,根本解决方案是直接使用官方 API。
作者还指出,如果实在无法访问官方 API,则必须进行验证后再使用。
7.2 审计验证的技巧
作者提出了一套四阶段验证流水线,如任一阶段失败就应避免使用该Endpoint:
| 阶段 | 验证方法 | 失败条件 |
|---|---|---|
| 1. 指纹验证 | ≥24 个 LLMmap 探测 | 余弦距离 > 1.2× 官方基线 或 识别模型不匹配 |
| 2. 分布检验 | MET 假设检验(≥500 样本,α=0.05) | 零假设被拒绝 |
| 3. 稳定性测试 | ≥3 次独立会话 | 准确率 SD > 5% 或 延迟 CV > 0.15 |
| 4. 合规检查 | ICP 备案、企业注册 | 无可验证的法律实体 |
7.3 研究者预注册清单
作者还提到,任何依赖 LLM API 的研究,数据收集前应公开报告:
1 | ## API 端点声明 |
7.4 社区层面行动
研究者呼吁:
- 会议组织者:更新审稿指南,将未披露或未验证的第三方 API Endpoint标记为存在可复现性风险
- 官方模型提供商:
- 放宽地区访问限制
- 提供学术定价
- 提供轻量级官方验证端点
“Official model providers can further reduce shadow market demand by relaxing geographic access restrictions, offering academic pricing tiers, and providing lightweight official verification endpoints…”
8. 局限性
论文承认的局限
- 时间窗口有限:研究只覆盖了 2025 年 9-12 月,影子 API 市场波动大,提供商频繁更换上游模型
- 缺乏 ground truth:没有影子 API 后端基础设施的真实信息,只能通过跑性能指标间接推断
- 覆盖面不全:只审计了 17 个提供商和 3 个模型家族,实际中转站的市场大得多
- 未覆盖的维度:模型自身的偏差、幻觉等的差异并未分析
个人观点
这篇论文揭示的问题,令我有几点感慨:
可复现性危机:如果 187 篇论文中相当一部分使用了不可靠的影子 API,那这些实验结果的可信度如何?引用这些论文的后续研究又如何?学术伦理何在?普通用户可能不在乎学术可复现性,但影子 API 的危害一样会影响到他们。例如你用某智能医疗问诊,它给你的建议背后可能来自一个不准确的廉价模型,论文中有一个案例:Gemini-2.5-flash 在官方 API 上 MedQA 准确率是 83.82%,但在影子 API 上只有 37%。
开源模型的伪装能力:没想到 Qwen2.5-7B 能冒充 GPT-4o-mini,GLM-4-9B 能冒充 GPT-5,这是不是说明开源模型的能力已经足够接近闭源模型,以至于用户难以通过表面交互区分?
验证成本:LLMmap 和 MET 都是比较专业的验证工具,普通用户根本不会用。有没有更简单的方法让用户知道自己被坑了?作为一个普通开发者,我怎么知道自己被坑了?
使用中转站不只是模型被替换风险,还有一个大问题论文作者忽略了,数据隐私安全风险!这些影子 API 作为中间人是否会泄露/转卖用户与LLM交互的数据?比如卖给模型厂商用于训练,这些可都是真实、有价值的数据。当然,这只是我的恶意揣测,没有实锤~
总结
这篇论文做了第一件系统性地审计影子 API 的事,发现了:
- 影子 API 已被 187 篇学术论文使用,最热门的一个有 5,966 次引用
- 45.83% 的端点无法通过模型指纹验证
- 性能差异高达 47.21%,医疗法律等敏感领域尤其不可靠
- GPT-5 被替换成 GLM-4-9B,GPT-4o-mini 被替换成 Qwen2.5-7B
- 用户支付官方价格,但只收到 36-52% 的实际价值
- 推理延迟波动可达官方的 10 倍以上
核心教训:如果你在做严肃的 LLM 研究,请务必使用官方 API。如果实在不行,至少要做验证,不然你根本不知道自己在用什么。此外,数据隐私安全风险也不能被忽视。论文作者可能因为无法验证这一点所以没提及。但作为用户,这是潜在风险点。
当你在用某个便宜又方便的第三方 API 时,你付出的代价可能远不止那点 token 钱
名词解释
| 术语 | 解释 |
|---|---|
| Shadow API(影子 API) | 第三方 LLM API 服务,特点是间接访问和突破地区限制 |
| LLMmap | 一种主动指纹识别框架,通过分析模型响应模式识别底层模型 |
| MET(Model Equality Testing) | 模型等价性测试,统计检验两个 API 输出是否来自同一分布 |
| OneAPI/NewAPI | 开源的 LLM 聚合和分发系统,影子 API 的常见基础设施 |
| Cosine Distance(余弦距离) | 衡量两个向量相似度的指标,越小越相似 |
| ICP 备案 | 中国互联网内容提供商备案制度 |
References
- Real Money, Fake Models: Deceptive Model Claims in Shadow APIs - 论文原文
- LLMmap: Fingerprinting for Large Language Models - arXiv:2407.15847
- Model Equality Testing: Which Model Is This API Serving? - arXiv:2410.20247
- Model Equality Testing: https://github.com/i-gao/model-equality-testing
- OneAPI - 开源 LLM 聚合系统
- JailbreakBench arXiv:2404.01318 - 越狱攻击基准测试
- GPQA: A Graduate-Level Google-Proof Q&A Benchmark arXiv:2311.12022
- MedQA (USMLE)arXiv:2104.08433 - 美国执业医师考试数据集
- LegalBench arXiv:2308.11462 - 法律推理基准测试
Author: Yrom
Link: https://yrom.net/blog/2026/03/06/paper-reading-shadow-api/
License: 知识共享署名-非商业性使用 4.0 国际许可协议